Speeding-up your dataset-creation process
Introduction
Unlike most academia, Industrial problems won’t come with a gold-standard dataset. Also, Dataset creation is not valued heavily in Industrial setting because it’s perceived more as a pain-in-the-xxx than a part-of-the-solution for numerous reasons. Few of them are,
- It is a manually taxing procedure.
- You don’t know how much data is enough. One must push deadlines for the project since there’s a clear dependency on the data.
- Your Data Scientists might take it to their ego if asked to spend time on labeling data. (Note: If you’re one of them, spend time in atleast understanding the edge cases.)
Telling that you need a lot of training data to get a high quality ML model is like saying “You need a lot of money to be rich”. - Christopher Ré, Snorkel
While the data-dependency sounds like a redundant fact, it comes with an operational overhead. So, this post talks about how to deal with this situation and speed up your project. It also highlights that the role of Data Scientists is not just to create a DL-Architecture at the end but to participate in the whole project-cycle.
Automating the process
1. Seed Data:
When the project starts, you don’t want to make your Data-Scientists sit idle until the data arrives. Instead, make it a continuous loop and involve your Data-Scientists from Day-1.
Getting the seed data enables you to fix the pipeline first i.e Training data format, annotation tool, the ML/DL architecture setup and the output format.
There are two options/way to get the seed-data,
1. Manual intervention
2. Automation
Option #1 -> Manual intervention:
This option is straightforward in asking annotators to label small amout of instances but this is not a desired scenario because
- It demands a lot of effort from annotators in creating a gold-standard dataset. And this small data may cover only a small distribution of the data.
- Your Data-Scientistis are still not putting any effort to understand the domain & problem. But the plus-side is that they can start working on the project-pipeline.
Option #2 -> Getting noisy data:
In this option, a set of observations on the data are given by the domain-expert to Data-Scientists, expecting them to translate observations into rule-based functions for annotating the unlabelled instances. Although not perfect, this is solving two things for you,
- Domain expertise is infused into the pipeline and this serves as your baseline.
- Converting observations to code helps the data-scientist in understanding the problem better by glancing at the distribution of the data. Although I hate the case of prognosticating accuracy before modelling, this approach helps a Data-Scientist to understand how easy/tough the problem is and to predict the accuracy to some certain extent.
So, considering the advantages above, we’ll be focussing on developing Option #2 in this post.
Note: If rule-based functions are magically covering the whole data distribution, we wouldn’t be needing an AI Savior. And we must admit that this seed data is no where an exact approximation of the whole data-distribution. So, this is where we need a Human-in-loop interface to enhance the seed-data.
2. Human-in-loop:
With the predictions from rule-based functions, you have two objectives now,
- Re-annotating the noisy predictions for training an ML model.
- Refining your rule-based functions for a robust baseline. This may even outperform your ML model.
2.1 Tools for annotation:
These are exciting times to live. There are some great open-source annotation tools for us to use. Pick the one that suits your requirement. For this post, I’m taking Named-Entity-Recognition as the task and label-studio as the annotation tool.
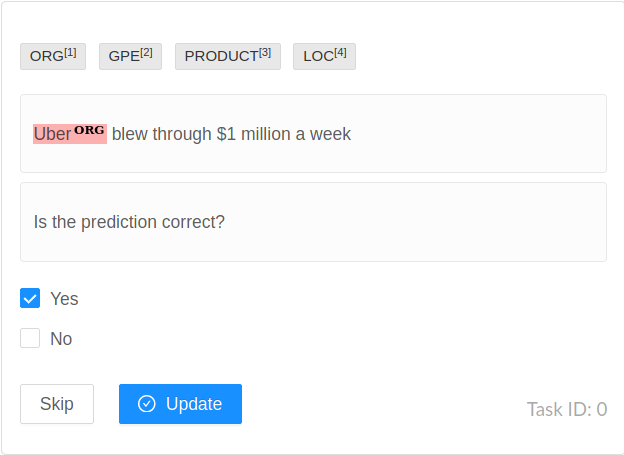
Label-Studio.
2.2 Pipeline for annotation
In addition to re-annotating your instances, validate your predictions into Yes/No category. If it’s a YES, you can send them straight into an ML model. Otherwise, depending on your bandwidth, either update the rules again or just train the ML model on re-annotated/NO-labelled instances.
YES-> Rules succeded at identifying entities.
NO-> Rules failed at identifying entities.
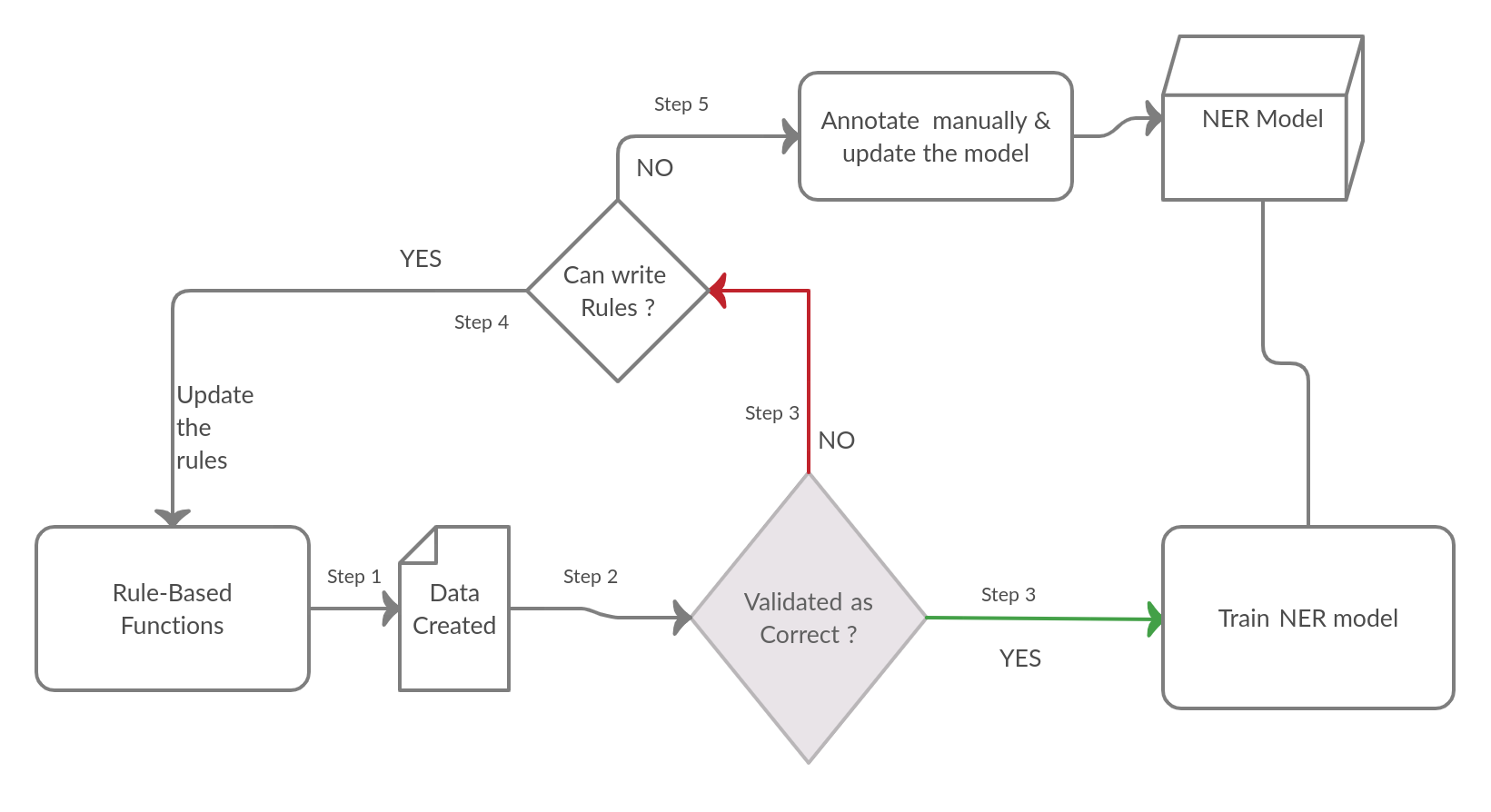
Make sure that your pipeline of Seed-Data -> Annotation Tool -> Verified Data is connected properly so that you can do as many as iterations as possible.
2.2.1 Visualizing the steps
Your noisy data at the end of Step-2 would look something like this,
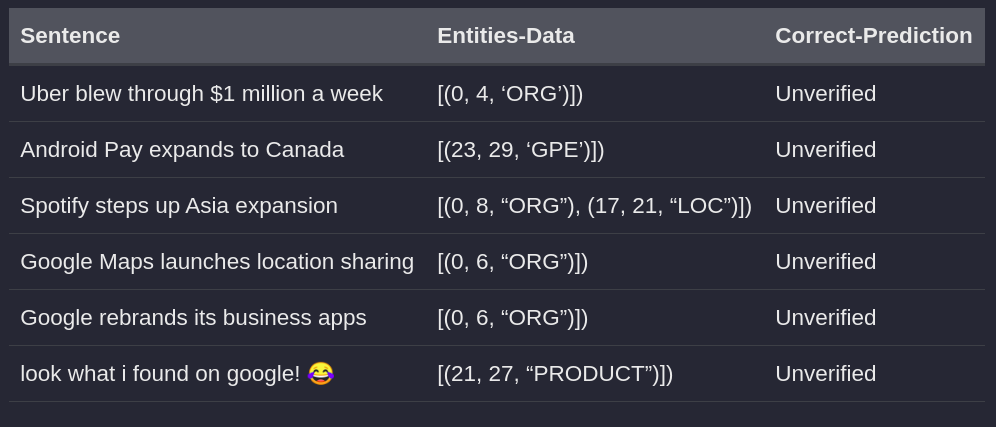
After validating & re-annotating your noisy data, this is the output you’d be getting for Step-3 (left) & Step-4 (right),


Note: The objective of using Yes/No is update the rule-based functions. We re-annotate the wronly-predicted instances but validate it as No to let the Data-Scientist know where rules fail.
Conclusion
Q) Demanding domain-expertise for rule-based functions sounds like we’re dating back to the pre-deep-learning era of feature-engineering. Isn’t it counter-productive?
Ans. Our objective of rules is to support the ML model not deliver a complete rule-based solution. For instance, let’s consider an example,
Uber raised $1 million from the initial IPO.
From a rules perspective, you might just do a lookup on 100-popular companies and tag any sub-string that matches the company as an entity. But from the ML perspective, it considers the context rather than just the word. Hence, if 60% of your data can be covered with rules and we train an ML model on the 60%, chances are that ML will bring in a deeper-perspective to cover the remaining 40%.
Q) Any alternatives to rule-based functions?
Ans. If an off-shelf ML model matches the problem or its domain, one can use that for the 1st iteration of data.
That’s it from my side. Hope you find this post useful.
Thanks,
Murali Manohar.


Leave a comment