ML2-Project-Submission
Murali Manohar
01/02/2022
1. Data
Data source: https://www.cs.cornell.edu/people/pabo/movie-review-data/
The data is released as a part of the paper Thumbs up? Sentiment classification using machine learning techniques. This dataset contains 1386 movie reviews classified into two sentiment levels - positive and negative. The reviews, present as .txt files, are stored in a folder mentioning the class label. It means, we have two folders neg & pos, which contain 692 and 694 .txt files.
Naturally, this is a supervised classification problem. So, we need a Machine Learning model which learns how to predict the polarity (+ve/-ve) of a movie review given the text.
Our final objective is to build an efficient & accurate ML model. The possible target values are negative & positive. There are a lot of metrics to base the model’s performance on. In our case, we will be using Accuracy metric.
The reviews are processed down-cased text files. This is both a blessing and curse. It’s a curse because capitalization acts an important feature and it’s also a blessing since we have a limit on the number of input features to the ML model. So, we continue using the lower-cased text files.
We can lower the number of input features further using Stemming/Lemmatization. Redundant features like stop words can also be removed.
Since the dataset is present in folder structure format, we start by loading it into our notebook using DirSource function. DirSource is used to read the documents inside a directory and store them all in a bucket. Next, we pass this DirSource object to VCorpus function. VCorpus stands for Volatile Corpora Structure, which is a standard tm object that is suitable for performing most tm functions.
library(tm)## Loading required package: NLPneg_reviews = VCorpus(DirSource("data/mix20_rand700_tokens_0211/tokens/neg/"),readerControl=list(language="en"))
pos_reviews = VCorpus(DirSource("data/mix20_rand700_tokens_0211/tokens/pos/"),readerControl = list(language="en"))
neg_reviews # dimension of the corpus## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 692inspect(neg_reviews[1]) # first document of the corpus## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 1
##
## [[1]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 3217inspect(neg_reviews[1:3]) # first three documents of the corpus## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 3
##
## [[1]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 3217
##
## [[2]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 6143
##
## [[3]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 1767neg_reviews[[1]]$content## [1] "tristar / 1 : 30 / 1997 / r ( language , violence , dennis rodman ) cast : jean-claude van damme ; mickey rourke ; dennis rodman ; natacha lindinger ; paul freeman director : tsui hark screenplay : dan jakoby ; paul mones ripe with explosions , mass death and really weird hairdos , tsui hark's \" double team \" must be the result of a tipsy hollywood power lunch that decided jean-claude van damme needs another notch on his bad movie-bedpost and nba superstar dennis rodman should have an acting career . actually , in \" double team , \" neither's performance is all that bad . i've always been the one critic to defend van damme -- he possesses a high charisma level that some genre stars ( namely steven seagal ) never aim for ; it's just that he's never made a movie so exuberantly witty since 1994's \" timecop . \" and rodman . . . well , he's pretty much rodman . he's extremely colorful , and therefore he pretty much fits his role to a t , even if the role is that of an ex-cia weapons expert . it's the story that needs some major work . van damme plays counter-terrorist operative jack quinn , who teams up with arms dealer yaz ( rodman ) to rub out deadly gangster stavros ( mickey rourke , all beefy and weird-looking ) in an antwerp amusement park . the job is botched when stavros' son gets killed in the gunfire , and quinn is taken off to an island known as \" the colony \" -- a think tank for soldiers \" too valuable to kill \" but \" too dangerous to set free . \" quinn escapes and tries to make it back home to his pregnant wife ( natacha lindinger ) , but stavros is out for revenge and kidnaps her . so , what's a kickboxing mercenary to do ? quinn looks up yaz and the two travel to rome so they can rescue the woman , kill stavros , save the world and do whatever else the screenplay requires them to do . with crazy , often eye-popping camera work by peter pau and rodman's lite brite locks , \" double team \" should be a mildly enjoyable guilty pleasure . but too much tries to happen in each frame , and the result is a movie that leaves you exhausted rather than exhilarated . the numerous action scenes are loud and headache-inducing and the frenetic pacing never slows down enough for us to care about what's going on in the movie . and much of what's going on is just wacky . there's a whole segment devoted to net-surfing monks that i have yet to figure out . and the climax finds quinn going head-to-head with a tiger in the roman coliseum while yaz circles them on a motorcycle , trying to avoid running over land mines and hold on to quinn's baby boy ( who's in a bomb equipped basket ) -- all this while stavros watches shirtless from the bleachers . did i mention \" double team \" is strange ? when it all comes down , this is just another rarely entertaining formula killathon , albeit one that feels no need to indulge in gratuitous profanity . rodman juices things up with his blatantly vibrant screen persona , though , leading up to a stunt where he kicks an opponent between the legs . but we didn't need \" double team \" to tell us he could do that , did we ? <a9> 1997 jamie peck e-mail : jpeck1@gl . umbc . edu visit the reel deal online : http : //www . gl . umbc . edu/~jpeck1/ "Negative reviews are stored in neg_reviews variable and positive ones in pos_reviews. As mentioned above, they are VCorpus objects. One can peel off the abstraction by going through the environment section in R. inspect function is helpful in understanding the data-type of the object and contents in it. It shows that there are two main keys: metadata and content. If we want to look at a particular index’s text data, we can use neg_reviews[[1]]\\$content.
This piece of code will take the first instance of neg_reviews and accesses the content attribute, which is where our textual data is stored.
2. Now, Preprocessing
Preprocessing: A series of operations performed to normalize the dataset. These operations include, but are not limited to, lower-casing, removing unwanted characters, stemming, stopword removal, etc.
Since these operations must be same for both positive & negative reviews, we combine them into one big variable called reviews and perform operations on this object. We combine them using the c() function. The resulting variable reviews contains 1386 documents.
tm_map function is used to map a data object with a function. To be specific, it takes a data object and a function as an input and applies that function on each entry of the data object and returns the result.
?getTransformations returns the list of available transformations
‘removeNumbers’, ‘removePunctuation’, ‘removeWords’, ‘stemDocument’, and ‘stripWhitespace’. The names of the functions are intuitive enough to understand what they mean. We can also apply custom functions but convert them to suitable tm_map format by wrapping them around with content_transformer.
Inorder to pass the arguments, we can use options(argument_name) inside tm_map. For example,
removeNumbers has an argument called ucp - a logical specifying whether to use Unicode character properties for determining digit characters. If FALSE (default), characters in the ASCII [:digit:] class (i.e., the decimal digits from 0 to 9) are taken; if TRUE, the characters with Unicode general category Nd (Decimal_Number).
So, we can use tm_map(reviews,removeNumbers, options=(ucp=FALSE)) to send our arguments.
reviews=c(neg_reviews,pos_reviews) # merge, concatenate both groups-corpuses
reviews_post=tm_map(reviews,removeNumbers, options=(ucp=FALSE))
reviews_post=tm_map(reviews_post,removePunctuation) # Remove punctuations
reviews_post=tm_map(reviews_post, content_transformer(tolower)) # convert to lowercaseBy perusing the dataset, it is observed that the web links are pre-tokenized i.e http://www.google.com is now split up as http: / / www. google. com. This limits us from applying regex. So, we add these tokens to the list of stop words that will be removed.
# stopwords() function returns the list of stop words for a given language.
# We use this list
english_stopwords = stopwords("english") # list of english stopwords
english_stopwords = append(english_stopwords, c("http","http:", "https:","/","www.",".edu",".com",".in",".eu"))
reviews_post=tm_map(reviews_post,removeWords,stopwords("english"))Lemmatization and stemming are special cases of normalization. The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. However, the outputs are different.
Stemming is more rudimentary and chops off suffixes often resulting in out-of-vocabulary words. And Lemmatization follows morphological analysis, aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. So, Lemmatization performs better than Stemming. Hence, we will be lemmatizing the corpus.
library textstem contains a function called lemmatize_strings, which performs lemmatization. The other way of applying a function (other than tm_map) is shown below. It is a naive approach. We go through each document, update it and go to the next.
reviews_post=tm_map(reviews_post,stripWhitespace) # To remove any extra white spaces
library(textstem)## Loading required package: koRpus.lang.en## Loading required package: koRpus## Loading required package: sylly## For information on available language packages for 'koRpus', run
##
## available.koRpus.lang()
##
## and see ?install.koRpus.lang()##
## Attaching package: 'koRpus'## The following object is masked from 'package:tm':
##
## readTagged# Lemmatize the data
for (i in 1:length(reviews_post)) {reviews_post[[i]]["content"]<-lemmatize_strings(reviews_post[[i]]["content"])}3. Featurize
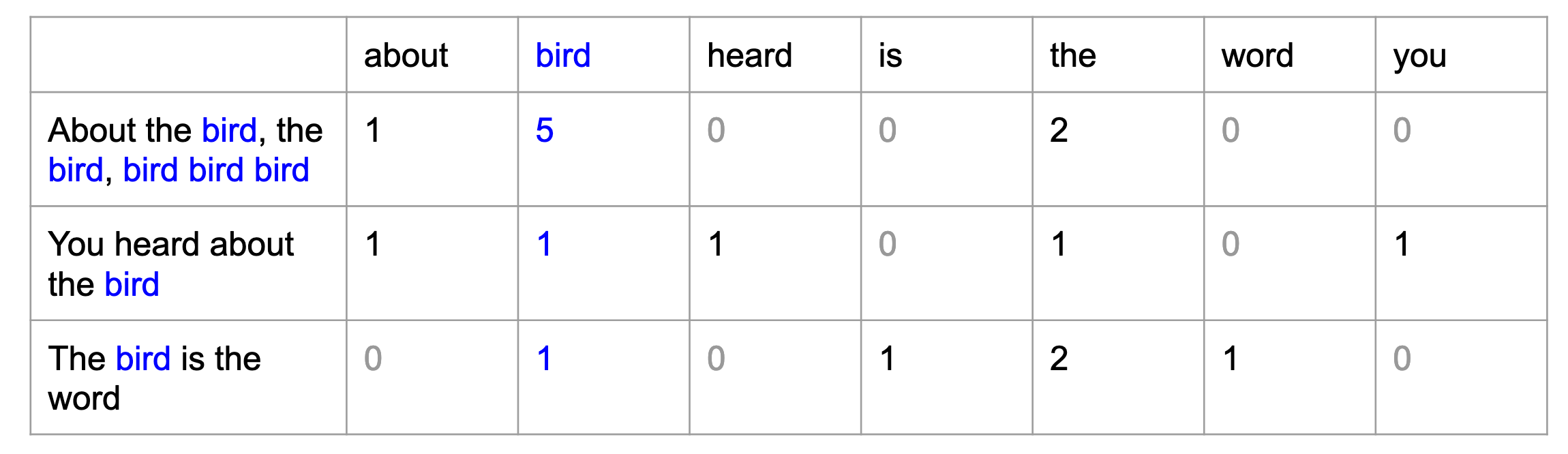
After pre-processing the movie review text files, we need to convert it into a format suitable for ML models. For Machine Learning, inputs are numeric, mostly in the form of matrices. So, we need to convert our text files into a matrix, where each word is a feature/column and each row represents a document/review. Bag-of-words is a concept where we store a data point in terms of a vector where each feature is a word’s frequency.

reference: source
{kind=link}
R has a function called DocumentTermMatrix which converts the documents into a Document-Term matrix. With the resulting matrix, we can find many inherent details using statistical techniques.
reviews_post_dtm=DocumentTermMatrix(reviews_post)
dim(reviews_post_dtm)## [1] 1386 31559dim function gives the shape of an input matrix. In our case, it is 1386 x 31559.
1386 rows - Documents
31559 columns - Words
Let’s look at a patch/subset of the matrix
inspect(reviews_post_dtm[15:25,1040:1044]) # inspecting a subset of the matrix## <<DocumentTermMatrix (documents: 11, terms: 5)>>
## Non-/sparse entries: 0/55
## Sparsity : 100%
## Maximal term length: 16
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs anthrozoologists anti antiappeal antic anticharm
## cv014_tok-12391.txt 0 0 0 0 0
## cv015_tok-23730.txt 0 0 0 0 0
## cv016_tok-16970.txt 0 0 0 0 0
## cv017_tok-27221.txt 0 0 0 0 0
## cv017_tok-29801.txt 0 0 0 0 0
## cv018_tok-11502.txt 0 0 0 0 0
## cv019_tok-2003.txt 0 0 0 0 0
## cv020_tok-13096.txt 0 0 0 0 0
## cv021_tok-29141.txt 0 0 0 0 0
## cv022_tok-25633.txt 0 0 0 0 0
## cv023_tok-25625.txt 0 0 0 0 0As we can see, the rows are documents and columns are words.
terms_with_min_freq_15 = findFreqTerms(reviews_post_dtm,15)
youngassoc = findAssocs(reviews_post_dtm,term="young",corlimit=0.7)
reviews_post_dtm.70=removeSparseTerms(reviews_post_dtm,sparse=0.7)
reviews_post_dtm.70 # or dim(sci.rel.dtm.70)## <<DocumentTermMatrix (documents: 1386, terms: 100)>>
## Non-/sparse entries: 63031/75569
## Sparsity : 55%
## Maximal term length: 11
## Weighting : term frequency (tf)# note that the term-document matrix needs to be transformed (casted)
# to a matrix form in the following barplot command
barplot(as.matrix(reviews_post_dtm.70),xlab="terms",ylab="number of occurrences",
main="Most frequent terms (sparseness=0.7)")
reviews_post_dtm.80=removeSparseTerms(reviews_post_dtm,sparse=0.8)
reviews_post_dtm.80## <<DocumentTermMatrix (documents: 1386, terms: 186)>>
## Non-/sparse entries: 92179/165617
## Sparsity : 64%
## Maximal term length: 11
## Weighting : term frequency (tf)reviews_post_dtm.90=removeSparseTerms(reviews_post_dtm,sparse=0.9)
reviews_post_dtm.90## <<DocumentTermMatrix (documents: 1386, terms: 470)>>
## Non-/sparse entries: 146913/504507
## Sparsity : 77%
## Maximal term length: 13
## Weighting : term frequency (tf)reviews_post_dtm.95=removeSparseTerms(reviews_post_dtm,sparse=0.95)
reviews_post_dtm.95## <<DocumentTermMatrix (documents: 1386, terms: 992)>>
## Non-/sparse entries: 197527/1177385
## Sparsity : 86%
## Maximal term length: 14
## Weighting : term frequency (tf)Find words that have a correlation of a particular threshold
findAssocs(reviews_post_dtm,term="love",corlimit=0.2)## $love
## marry shakespeare stoppard apothecary
## 0.29 0.29 0.28 0.26
## atchesonplaywright boundless couplet fennymann
## 0.26 0.26 0.26 0.26
## financiallyoriented gigliotti henslowe iambic
## 0.26 0.26 0.26 0.26
## marlowes openlyhomosexual pentameter rozencrantz
## 0.26 0.26 0.26 0.26
## slimeball wessex firth lesseps
## 0.26 0.26 0.24 0.24
## madden relationship viola harmonize
## 0.24 0.24 0.24 0.22
## parfitt dench norman passionate
## 0.22 0.21 0.21 0.21
## venice shakespeares
## 0.21 0.204. Visualize wordclouds for both negative & positive reviews
- Wordcloud on Positive reviews
library(wordcloud2)
# calculate the frequency of words and sort in descending order.
# Positive
wordFreqs=sort(colSums(as.matrix(reviews_post_dtm.90)[692:1386,]),decreasing=TRUE)
dataframe_4_wordcloud = data.frame("word" = names(wordFreqs), "freq" = wordFreqs)
wordcloud2(dataframe_4_wordcloud)- Wordcloud on
Negativereviews
# calculate the frequency of words and sort in descending order.
# Negative
wordFreqs=sort(colSums(as.matrix(reviews_post_dtm.90)[0:692,]),decreasing=TRUE)
dataframe_4_wordcloud = data.frame("word" = names(wordFreqs), "freq" = wordFreqs)
wordcloud2(dataframe_4_wordcloud)There are some-rendering issues while converting to .html file. The second wordcloud was not converting properly. So, loading it like this. 
5. Supervised Learning Dataset creation
Since we’re making Supervised learning, we need to have labels for the data points. Add the label column and name it as classlabeltype. Convert the matrix into a dataframe for further ML operations.
data=data.frame(as.matrix(reviews_post_dtm.90)) # convert corpus to dataFrame format
classlabeltype = c(rep("negative",692),rep("positive",694)) # create the type vector to be appended
data = cbind(data,classlabeltype)
colnames(data)[ncol(data)]="classlabeltype"head(data)Write the data into weka format (.arff)
library(foreign)
write.arff(data,file="term-document-matrix-weka-format-for-rottentomatoes.arff")6. Convert features (word-frequency) into numeric and label to categorical.
outcomeName = 'classlabeltype'
predictors<-names(data)[!names(data) %in% outcomeName] # All features except class
# Convert all word frequency features to numeric.
data$classlabeltype =as.factor(data$classlabeltype)
data[is.na(data)] <- 0 #Replace NA with 0
for (k in predictors) {
data[[k]] <- as.numeric(data[[k]])
}7. Remove outliers
In the dataset, there can be a few outliers/anomalies which can, utmost, hinder the model from learning better relations b/w features. Inorder to prevent this, we find out the outliers and remove them from the corpus.
We use IsolationForest method from solitude library. IsolationForest computes an isolation score for each datapoint which will help us in identifying the outlierness.
library(solitude) #Importing the library for outlier detection
iso <- isolationForest$new()
iso$fit(data[,-ncol(data)]) # Fit the dataset## INFO [00:20:21.449] dataset has duplicated rows
## INFO [00:20:21.477] Building Isolation Forest ...
## INFO [00:20:21.908] done
## INFO [00:20:21.909] Computing depth of terminal nodes ...
## INFO [00:20:22.207] done
## INFO [00:20:22.257] Completed growing isolation forest#-ncol(data) refers to the last column i.e class column
p <- iso$predict(data[,-ncol(data)]) # Now, predict on the data to get isolation scores. Variable `p` has the isolation scores of each datapoint.Now, sort the scores and plot the data
sort(p$anomaly_score) #Sort the scores## [1] 0.5820092 0.5820092 0.5820092 0.5820092 0.5820092 0.5820092 0.5820092
## [8] 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031
## [15] 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031 0.5824031
## [22] 0.5824031 0.5827973 0.5827973 0.5827973 0.5827973 0.5827973 0.5827973
## [29] 0.5827973 0.5827973 0.5827973 0.5827973 0.5827973 0.5827973 0.5827973
## [36] 0.5827973 0.5827973 0.5827973 0.5827973 0.5831917 0.5831917 0.5831917
## [43] 0.5831917 0.5831917 0.5831917 0.5831917 0.5831917 0.5831917 0.5831917
## [50] 0.5831917 0.5831917 0.5831917 0.5831917 0.5831917 0.5831917 0.5835865
## [57] 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865
## [64] 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865
## [71] 0.5835865 0.5835865 0.5835865 0.5835865 0.5835865 0.5839814 0.5839814
## [78] 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814
## [85] 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814
## [92] 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814
## [99] 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814 0.5839814
## [106] 0.5839814 0.5839814 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767
## [113] 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767
## [120] 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767 0.5843767
## [127] 0.5843767 0.5843767 0.5843767 0.5847722 0.5847722 0.5847722 0.5847722
## [134] 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722
## [141] 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722 0.5847722
## [148] 0.5847722 0.5847722 0.5847722 0.5847722 0.5851680 0.5851680 0.5851680
## [155] 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680
## [162] 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680
## [169] 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680 0.5851680
## [176] 0.5851680 0.5851680 0.5851680 0.5851680 0.5855640 0.5855640 0.5855640
## [183] 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640
## [190] 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640 0.5855640
## [197] 0.5855640 0.5855640 0.5855640 0.5855640 0.5859603 0.5859603 0.5859603
## [204] 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603
## [211] 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603
## [218] 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603
## [225] 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603 0.5859603
## [232] 0.5859603 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569
## [239] 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569
## [246] 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569 0.5863569
## [253] 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538
## [260] 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538
## [267] 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538
## [274] 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538
## [281] 0.5867538 0.5867538 0.5867538 0.5867538 0.5867538 0.5871509 0.5871509
## [288] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509
## [295] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509
## [302] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509
## [309] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509
## [316] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509
## [323] 0.5871509 0.5871509 0.5871509 0.5871509 0.5871509 0.5875483 0.5875483
## [330] 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483
## [337] 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483
## [344] 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483
## [351] 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483 0.5875483
## [358] 0.5875483 0.5875483 0.5875483 0.5879460 0.5879460 0.5879460 0.5879460
## [365] 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460
## [372] 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460 0.5879460
## [379] 0.5879460 0.5879460 0.5879460 0.5883439 0.5883439 0.5883439 0.5883439
## [386] 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439
## [393] 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439
## [400] 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439
## [407] 0.5883439 0.5883439 0.5883439 0.5883439 0.5883439 0.5887421 0.5887421
## [414] 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421
## [421] 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421
## [428] 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421
## [435] 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421 0.5887421
## [442] 0.5887421 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406
## [449] 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406
## [456] 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406
## [463] 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5891406 0.5895393
## [470] 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393
## [477] 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393
## [484] 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393
## [491] 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393
## [498] 0.5895393 0.5895393 0.5895393 0.5895393 0.5895393 0.5899383 0.5899383
## [505] 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383
## [512] 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383
## [519] 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383
## [526] 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383
## [533] 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383 0.5899383
## [540] 0.5899383 0.5899383 0.5899383 0.5903376 0.5903376 0.5903376 0.5903376
## [547] 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376
## [554] 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376
## [561] 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376 0.5903376
## [568] 0.5903376 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371
## [575] 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371
## [582] 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371
## [589] 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5907371 0.5911370
## [596] 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370
## [603] 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370
## [610] 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370
## [617] 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370
## [624] 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370 0.5911370
## [631] 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371
## [638] 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371
## [645] 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371 0.5915371
## [652] 0.5915371 0.5915371 0.5915371 0.5919374 0.5919374 0.5919374 0.5919374
## [659] 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374
## [666] 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374
## [673] 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374
## [680] 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374
## [687] 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374 0.5919374
## [694] 0.5919374 0.5919374 0.5919374 0.5923381 0.5923381 0.5923381 0.5923381
## [701] 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381
## [708] 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381
## [715] 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381 0.5923381
## [722] 0.5923381 0.5923381 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390
## [729] 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390
## [736] 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390
## [743] 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390
## [750] 0.5927390 0.5927390 0.5927390 0.5927390 0.5927390 0.5931401 0.5931401
## [757] 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401
## [764] 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401
## [771] 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401 0.5931401
## [778] 0.5931401 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416
## [785] 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416
## [792] 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416
## [799] 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416 0.5935416
## [806] 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433
## [813] 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433
## [820] 0.5939433 0.5939433 0.5939433 0.5939433 0.5939433 0.5943453 0.5943453
## [827] 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453
## [834] 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453
## [841] 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453
## [848] 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453 0.5943453
## [855] 0.5943453 0.5943453 0.5943453 0.5943453 0.5947475 0.5947475 0.5947475
## [862] 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475
## [869] 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475
## [876] 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5947475 0.5951501
## [883] 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501
## [890] 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501
## [897] 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501
## [904] 0.5951501 0.5951501 0.5951501 0.5951501 0.5951501 0.5955529 0.5955529
## [911] 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529
## [918] 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529
## [925] 0.5955529 0.5955529 0.5955529 0.5955529 0.5955529 0.5959560 0.5959560
## [932] 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560
## [939] 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560
## [946] 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560
## [953] 0.5959560 0.5959560 0.5959560 0.5959560 0.5959560 0.5963593 0.5963593
## [960] 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593
## [967] 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593 0.5963593
## [974] 0.5963593 0.5963593 0.5963593 0.5967629 0.5967629 0.5967629 0.5967629
## [981] 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629
## [988] 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629
## [995] 0.5967629 0.5967629 0.5967629 0.5967629 0.5967629 0.5971668 0.5971668
## [1002] 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668
## [1009] 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668 0.5971668
## [1016] 0.5971668 0.5971668 0.5971668 0.5971668 0.5975710 0.5975710 0.5975710
## [1023] 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710
## [1030] 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710
## [1037] 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5975710 0.5979755
## [1044] 0.5979755 0.5979755 0.5979755 0.5979755 0.5979755 0.5979755 0.5979755
## [1051] 0.5979755 0.5979755 0.5979755 0.5979755 0.5979755 0.5979755 0.5983802
## [1058] 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802
## [1065] 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802 0.5983802
## [1072] 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852
## [1079] 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852
## [1086] 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5987852 0.5991904
## [1093] 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904
## [1100] 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904 0.5991904
## [1107] 0.5991904 0.5995960 0.5995960 0.5995960 0.5995960 0.5995960 0.5995960
## [1114] 0.5995960 0.5995960 0.5995960 0.5995960 0.5995960 0.5995960 0.5995960
## [1121] 0.5995960 0.6000018 0.6000018 0.6000018 0.6000018 0.6000018 0.6000018
## [1128] 0.6000018 0.6000018 0.6000018 0.6000018 0.6000018 0.6000018 0.6000018
## [1135] 0.6000018 0.6004079 0.6004079 0.6004079 0.6004079 0.6004079 0.6004079
## [1142] 0.6004079 0.6004079 0.6004079 0.6008142 0.6008142 0.6008142 0.6008142
## [1149] 0.6008142 0.6008142 0.6008142 0.6008142 0.6008142 0.6008142 0.6008142
## [1156] 0.6008142 0.6008142 0.6008142 0.6008142 0.6012209 0.6012209 0.6012209
## [1163] 0.6012209 0.6012209 0.6012209 0.6012209 0.6012209 0.6012209 0.6012209
## [1170] 0.6016278 0.6016278 0.6016278 0.6016278 0.6016278 0.6016278 0.6016278
## [1177] 0.6016278 0.6020350 0.6020350 0.6020350 0.6020350 0.6020350 0.6020350
## [1184] 0.6020350 0.6020350 0.6020350 0.6020350 0.6020350 0.6020350 0.6020350
## [1191] 0.6020350 0.6020350 0.6020350 0.6024425 0.6024425 0.6024425 0.6024425
## [1198] 0.6024425 0.6024425 0.6024425 0.6024425 0.6024425 0.6024425 0.6024425
## [1205] 0.6024425 0.6024425 0.6024425 0.6024425 0.6024425 0.6028502 0.6028502
## [1212] 0.6028502 0.6028502 0.6028502 0.6028502 0.6028502 0.6032582 0.6032582
## [1219] 0.6032582 0.6032582 0.6036665 0.6036665 0.6036665 0.6036665 0.6036665
## [1226] 0.6036665 0.6036665 0.6036665 0.6036665 0.6040751 0.6040751 0.6040751
## [1233] 0.6040751 0.6040751 0.6040751 0.6040751 0.6040751 0.6040751 0.6040751
## [1240] 0.6040751 0.6040751 0.6044839 0.6044839 0.6044839 0.6044839 0.6044839
## [1247] 0.6044839 0.6044839 0.6048931 0.6048931 0.6048931 0.6053025 0.6053025
## [1254] 0.6053025 0.6053025 0.6053025 0.6053025 0.6053025 0.6053025 0.6057121
## [1261] 0.6057121 0.6057121 0.6057121 0.6057121 0.6057121 0.6061221 0.6061221
## [1268] 0.6061221 0.6061221 0.6061221 0.6061221 0.6065323 0.6065323 0.6065323
## [1275] 0.6069428 0.6069428 0.6069428 0.6069428 0.6069428 0.6069428 0.6069428
## [1282] 0.6069428 0.6069428 0.6069428 0.6073536 0.6073536 0.6073536 0.6077647
## [1289] 0.6077647 0.6077647 0.6077647 0.6081760 0.6081760 0.6081760 0.6081760
## [1296] 0.6081760 0.6081760 0.6085877 0.6085877 0.6085877 0.6085877 0.6089996
## [1303] 0.6089996 0.6089996 0.6089996 0.6089996 0.6089996 0.6089996 0.6094117
## [1310] 0.6094117 0.6094117 0.6094117 0.6098242 0.6098242 0.6098242 0.6098242
## [1317] 0.6098242 0.6102369 0.6102369 0.6106500 0.6106500 0.6110633 0.6110633
## [1324] 0.6110633 0.6110633 0.6110633 0.6114768 0.6114768 0.6114768 0.6118907
## [1331] 0.6118907 0.6127192 0.6127192 0.6127192 0.6131339 0.6131339 0.6131339
## [1338] 0.6131339 0.6135489 0.6135489 0.6139642 0.6139642 0.6143797 0.6147955
## [1345] 0.6152116 0.6152116 0.6152116 0.6152116 0.6160447 0.6160447 0.6160447
## [1352] 0.6164616 0.6168789 0.6168789 0.6168789 0.6172964 0.6172964 0.6172964
## [1359] 0.6177142 0.6177142 0.6177142 0.6181323 0.6181323 0.6185506 0.6185506
## [1366] 0.6185506 0.6189693 0.6198074 0.6198074 0.6198074 0.6206467 0.6206467
## [1373] 0.6210667 0.6214871 0.6219077 0.6227498 0.6240152 0.6240152 0.6244375
## [1380] 0.6257062 0.6278265 0.6286767 0.6312340 0.6316612 0.6320887 0.6381045plot(density(p$anomaly_score)) #Plot the data
From the plot, we could see that most datapoints fall under 0.58-0.61. Anything after 0.61 can be considered as outliers.
outliers = (which(p$anomaly_score > 0.61))
outliers## [1] 5 36 40 63 124 156 171 225 239 246 258 331 337 338 346
## [16] 348 444 456 488 555 565 656 706 708 734 758 762 779 781 805
## [31] 821 834 839 866 872 873 876 912 917 955 964 974 976 977 980
## [46] 998 1019 1020 1030 1036 1044 1050 1072 1096 1105 1129 1154 1171 1182 1195
## [61] 1202 1207 1224 1231 1235 1242 1295 1296 1341dim(data)## [1] 1386 471Remove the outlier instances from the data
data = data[-outliers,]dim(data)## [1] 1317 471We could see the change in dim(data). Earlier, it was 1386 x 471. Now, it is 1317 x 471. It means that certain data samples are removed.
7.1 Let’s see how many instances per class have been removed. Display the stats of each class in the dataset
table(data["classlabeltype"])##
## negative positive
## 670 647The Class distribution after removing the outliers has changed a little
8. Subsampling
Earlier, both the classes had almost similar distribution i.e negative 692 && positive 694. But now, the difference has increased. Although this difference is not much (23 more negative instances than positive ones), let’s use R’s subsampling method to have equal number of both class instances.
We have two options i.e upsampling & downsampling. Since ML models are data-hungry, let’s upsample our data using upSample function.
https://topepo.github.io/caret/subsampling-for-class-imbalances.html
library(caret) # Library for ML model training, hyper-parameter tuning, model comparison## Loading required package: ggplot2##
## Attaching package: 'ggplot2'## The following object is masked from 'package:NLP':
##
## annotate## Loading required package: latticedata <- upSample(x = data[, -ncol(data)],
y = (data$classlabeltype), yname="classlabeltype")
table(data$classlabeltype) ##
## negative positive
## 670 670We could see that both the classes have equal instances now
9. Clustering
Source: https://www.r-bloggers.com/2021/04/cluster-analysis-in-r/
library(ggplot2)
library(factoextra)## Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBa9.1 Visualize using kmeans
km <- kmeans(data[,-ncol(data)], centers = 2, nstart = 5)
# Visualize the clusters
fviz_cluster(km, data = data[,-ncol(data)])
9.2 Average Silhouette Method
The average silhouette approach measures the quality of a clustering. It determines how well each observation lies within its cluster.
A high average silhouette width indicates a good clustering. The average silhouette method computes the average silhouette of observations for different values of k. We can execute the same based on the below code.
fviz_nbclust(data[,-ncol(data)], kmeans, method = "silhouette")
We can see that the average silhouette method suggests 2 as the optimal number of clusters which is equal to the number of classes we have.
9.3 Hierarchical Clustering
distMatrix=dist(t(scale(as.matrix(reviews_post_dtm.70))))
termClustering=hclust(distMatrix,method="complete")
plot(termClustering)
10. Now, start the ML process
Make train test splits for ML
10.1 Split the data
https://www.rdocumentation.org/packages/caret/versions/6.0-90/topics/createDataPartition
set.seed(107) # a random seed to enable reproducibility
inTrain <- createDataPartition(y=data$classlabeltype,p=.75,list=FALSE)A series of test/training partitions are created using createDataPartition while createResample creates one or more bootstrap samples. createFolds splits the data into k groups while createTimeSlices creates cross-validation split for series data. groupKFold splits the data based on a grouping factor.
training <- data[inTrain,]
testing <- data[-inTrain,]
nrow(training)## [1] 1006head(training)11. Consult model names
modelnames <- paste(names(getModelInfo()), collapse=',')
modelnames## [1] "ada,AdaBag,AdaBoost.M1,adaboost,amdai,ANFIS,avNNet,awnb,awtan,bag,bagEarth,bagEarthGCV,bagFDA,bagFDAGCV,bam,bartMachine,bayesglm,binda,blackboost,blasso,blassoAveraged,bridge,brnn,BstLm,bstSm,bstTree,C5.0,C5.0Cost,C5.0Rules,C5.0Tree,cforest,chaid,CSimca,ctree,ctree2,cubist,dda,deepboost,DENFIS,dnn,dwdLinear,dwdPoly,dwdRadial,earth,elm,enet,evtree,extraTrees,fda,FH.GBML,FIR.DM,foba,FRBCS.CHI,FRBCS.W,FS.HGD,gam,gamboost,gamLoess,gamSpline,gaussprLinear,gaussprPoly,gaussprRadial,gbm_h2o,gbm,gcvEarth,GFS.FR.MOGUL,GFS.LT.RS,GFS.THRIFT,glm.nb,glm,glmboost,glmnet_h2o,glmnet,glmStepAIC,gpls,hda,hdda,hdrda,HYFIS,icr,J48,JRip,kernelpls,kknn,knn,krlsPoly,krlsRadial,lars,lars2,lasso,lda,lda2,leapBackward,leapForward,leapSeq,Linda,lm,lmStepAIC,LMT,loclda,logicBag,LogitBoost,logreg,lssvmLinear,lssvmPoly,lssvmRadial,lvq,M5,M5Rules,manb,mda,Mlda,mlp,mlpKerasDecay,mlpKerasDecayCost,mlpKerasDropout,mlpKerasDropoutCost,mlpML,mlpSGD,mlpWeightDecay,mlpWeightDecayML,monmlp,msaenet,multinom,mxnet,mxnetAdam,naive_bayes,nb,nbDiscrete,nbSearch,neuralnet,nnet,nnls,nodeHarvest,null,OneR,ordinalNet,ordinalRF,ORFlog,ORFpls,ORFridge,ORFsvm,ownn,pam,parRF,PART,partDSA,pcaNNet,pcr,pda,pda2,penalized,PenalizedLDA,plr,pls,plsRglm,polr,ppr,pre,PRIM,protoclass,qda,QdaCov,qrf,qrnn,randomGLM,ranger,rbf,rbfDDA,Rborist,rda,regLogistic,relaxo,rf,rFerns,RFlda,rfRules,ridge,rlda,rlm,rmda,rocc,rotationForest,rotationForestCp,rpart,rpart1SE,rpart2,rpartCost,rpartScore,rqlasso,rqnc,RRF,RRFglobal,rrlda,RSimca,rvmLinear,rvmPoly,rvmRadial,SBC,sda,sdwd,simpls,SLAVE,slda,smda,snn,sparseLDA,spikeslab,spls,stepLDA,stepQDA,superpc,svmBoundrangeString,svmExpoString,svmLinear,svmLinear2,svmLinear3,svmLinearWeights,svmLinearWeights2,svmPoly,svmRadial,svmRadialCost,svmRadialSigma,svmRadialWeights,svmSpectrumString,tan,tanSearch,treebag,vbmpRadial,vglmAdjCat,vglmContRatio,vglmCumulative,widekernelpls,WM,wsrf,xgbDART,xgbLinear,xgbTree,xyf"12. Model-1: Training & tuning
As a first model, we use Neural Networks nnet. Neural networks are preferred because of their non-linear activation functions. This non-linearity is useful in approximating the non-linear datasets. Specifically, we fit a single-hidden-layer neural network. As of now, we don’t use skip-connections. The possible parameters of this method are
weights => (case) weights for each example -- if missing defaults to 1. We don't disturb it. we weight all of the parameters equally.
size => number of units in the hidden layer. Can be zero if there are skip-layer units.
Wts => initial parameter vector. If missing chosen at random.
mask => logical vector indicating which parameters should be optimized (default all).
linout => switch for linear output units. Default logistic output units.
entropy => switch for entropy (= maximum conditional likelihood) fitting. Default by least-squares.
softmax => switch for softmax (log-linear model) and maximum conditional likelihood fitting. linout, entropy, softmax and censored are mutually exclusive.
censored => A variant on softmax, in which non-zero targets mean possible classes. Thus for softmax a row of (0, 1, 1) means one example each of classes 2 and 3, but for censored it means one example whose class is only known to be 2 or 3. skip switch to add skip-layer connections from input to output. rang Initial random weights on [-rang, rang]. Value about 0.5 unless the inputs are large, in which case it should be chosen so that rang * max(|x|) is about 1. decay parameter for weight decay. Default 0. maxit maximum number of iterations. Default 100. Hess If true, the Hessian of the measure of fit at the best set of weights found is returned as component Hessian. trace switch for tracing optimization. Default TRUE.
MaxNWts => The maximum allowable number of weights. There is no intrinsic limit in the code, but increasing MaxNWts will probably allow fits that are very slow and time-consuming.
abstol => Stop if the fit criterion falls below abstol, indicating an essentially perfect fit.
reltol => Stop if the optimizer is unable to reduce the fit criterion by a factor of at least 1 - reltol.12.1 Fix the training params
# fixing the performance estimation procedure
ctrl <- trainControl(method = "repeatedcv",repeats=3, number=10)The arguments of this function are
method => The resampling method: "boot", "boot632", "optimism_boot", "boot_all", "cv", "repeatedcv", "LOOCV", "LGOCV" (for repeated training/test splits), "none" (only fits one model to the entire training set), "oob" (only for random forest, bagged trees, bagged earth, bagged flexible discriminant analysis, or conditional tree forest models), timeslice, "adaptive_cv", "adaptive_boot" or "adaptive_LGOCV"
number => Either the number of folds or number of resampling iterations
repeats => For repeated k-fold cross-validation only: the number of complete sets of folds to compute
p => For leave-group out cross-validation: the training percentage
search => Either "grid" or "random", describing how the tuning parameter grid is determined. See details below.
verboseIter => A logical for printing a training log.
returnData => A logical for saving the data
returnResamp => A character string indicating how much of the resampled summary metrics should be saved. Values can be "final", "all" or "none"
savePredictions => an indicator of how much of the hold-out predictions for each resample should be saved. Values can be either "all", "final", or "none". A logical value can also be used that convert to "all" (for true) or "none" (for false). "final" saves the predictions for the optimal tuning parameters.
classProbs => a logical; should class probabilities be computed for classification models (along with predicted values) in each resample?
summaryFunction => a function to compute performance metrics across resamples. The arguments to the function should be the same as those in defaultSummary. Note that if method = "oob" is used, this option is ignored and a warning is issued.
selectionFunction => the function used to select the optimal tuning parameter. This can be a name of the function or the function itself. See best for details and other options.
preProcOptions => A list of options to pass to preProcess. The type of pre-processing (e.g. center, scaling etc) is passed in via the preProc option in train.
sampling => a single character value describing the type of additional sampling that is conducted after resampling (usually to resolve class imbalances). Values are "none", "down", "up", "smote", or "rose". The latter two values require the themis and ROSE packages, respectively. This argument can also be a list to facilitate custom sampling and these details can be found on the caret package website for sampling (link below).
index => a list with elements for each resampling iteration. Each list element is a vector of integers corresponding to the rows used for training at that iteration.
indexOut => a list (the same length as index) that dictates which data are held-out for each resample (as integers). If NULL, then the unique set of samples not contained in index is used.
indexFinal => an optional vector of integers indicating which samples are used to fit the final model after resampling. If NULL, then entire data set is used.
timingSamps => the number of training set samples that will be used to measure the time for predicting samples (zero indicates that the prediction time should not be estimated.
predictionBounds => a logical or numeric vector of length 2 (regression only). If logical, the predictions can be constrained to be within the limit of the training set outcomes. For example, a value of c(TRUE, FALSE) would only constrain the lower end of predictions. If numeric, specific bounds can be used. For example, if c(10, NA), values below 10 would be predicted as 10 (with no constraint in the upper side).
seeds => an optional set of integers that will be used to set the seed at each resampling iteration. This is useful when the models are run in parallel. A value of NA will stop the seed from being set within the worker processes while a value of NULL will set the seeds using a random set of integers. Alternatively, a list can be used. The list should have B+1 elements where B is the number of resamples, unless method is "boot632" in which case B is the number of resamples plus 1. The first B elements of the list should be vectors of integers of length M where M is the number of models being evaluated. The last element of the list only needs to be a single integer (for the final model). See the Examples section below and the Details section.
adaptive => a list used when method is "adaptive_cv", "adaptive_boot" or "adaptive_LGOCV". See Details below.
options(warn=-1)
model_nnet<-train(training[,predictors],training[,outcomeName],method='nnet', trControl=ctrl,tuneLength=3, maxit=300,
metric='Accuracy')## # weights: 473
## initial value 639.345985
## iter 10 value 522.415707
## iter 20 value 391.913514
## iter 30 value 324.456954
## iter 40 value 288.215992
## iter 50 value 264.535654
## iter 60 value 256.194943
## iter 70 value 251.590101
## iter 80 value 245.393262
## iter 90 value 244.956767
## iter 100 value 242.799239
## iter 110 value 233.937134
## iter 120 value 231.612198
## iter 130 value 231.071290
## iter 140 value 222.336248
## iter 150 value 218.059368
## iter 160 value 217.522694
## iter 170 value 215.203624
## iter 180 value 215.099580
## iter 190 value 215.094451
## iter 200 value 213.021844
## iter 210 value 212.655603
## iter 220 value 212.652254
## iter 230 value 209.622605
## iter 240 value 209.586701
## iter 250 value 206.469357
## iter 260 value 204.300672
## iter 270 value 204.183766
## iter 280 value 200.822920
## iter 290 value 200.815326
## iter 300 value 200.813244
## final value 200.813244
## stopped after 300 iterations
## # weights: 473
## initial value 715.984694
## iter 10 value 453.177900
## iter 20 value 389.234444
## iter 30 value 333.892224
## iter 40 value 280.491379
## iter 50 value 241.235625
## iter 60 value 213.883531
## iter 70 value 187.266451
## iter 80 value 172.990855
## iter 90 value 150.594179
## iter 100 value 141.485381
## iter 110 value 126.929506
## iter 120 value 114.632648
## iter 130 value 105.582066
## iter 140 value 89.523484
## iter 150 value 82.559285
## iter 160 value 75.057070
## iter 170 value 72.272735
## iter 180 value 69.839124
## iter 190 value 69.537394
## iter 200 value 63.966140
## iter 210 value 59.811884
## iter 220 value 57.942626
## iter 230 value 53.099602
## iter 240 value 52.204783
## iter 250 value 51.947034
## iter 260 value 49.947209
## iter 270 value 47.705071
## iter 280 value 47.196886
## iter 290 value 45.188088
## iter 300 value 44.669906
## final value 44.669906
## stopped after 300 iterations
## # weights: 473
## initial value 653.665745
## iter 10 value 508.042657
## iter 20 value 380.150983
## iter 30 value 356.537528
## iter 40 value 342.973948
## iter 50 value 337.019971
## iter 60 value 326.867637
## iter 70 value 321.226629
## iter 80 value 318.207405
## iter 90 value 313.501219
## iter 100 value 310.851749
## iter 110 value 306.241076
## iter 120 value 301.548142
## iter 130 value 296.904131
## iter 140 value 294.118745
## iter 150 value 288.550965
## iter 160 value 286.648688
## iter 170 value 285.445252
## iter 180 value 283.756735
## iter 190 value 281.851114
## iter 200 value 276.104670
## iter 210 value 275.914510
## iter 220 value 275.851760
## iter 230 value 264.608040
## iter 240 value 257.688714
## iter 250 value 249.691382
## iter 260 value 245.133155
## iter 270 value 244.157242
## iter 280 value 240.430746
## iter 290 value 236.224648
## iter 300 value 233.789106
## final value 233.789106
## stopped after 300 iterations
## # weights: 473
## initial value 650.918663
## iter 10 value 501.074904
## iter 20 value 451.611410
## iter 30 value 381.206174
## iter 40 value 309.721900
## iter 50 value 285.975528
## iter 60 value 285.763421
## iter 70 value 282.764053
## iter 80 value 280.786130
## iter 90 value 276.530397
## iter 100 value 275.221320
## iter 110 value 273.324847
## iter 120 value 273.306302
## iter 130 value 273.305551
## iter 140 value 273.074827
## iter 150 value 269.471725
## iter 160 value 269.294260
## iter 170 value 267.531038
## iter 180 value 267.529991
## iter 190 value 267.529624
## iter 190 value 267.529623
## iter 190 value 267.529623
## final value 267.529623
## converged
## # weights: 473
## initial value 647.124668
## iter 10 value 413.982461
## iter 20 value 336.779495
## iter 30 value 282.810222
## iter 40 value 226.732402
## iter 50 value 185.056700
## iter 60 value 168.021137
## iter 70 value 145.134534
## iter 80 value 113.136247
## iter 90 value 96.217430
## iter 100 value 87.559755
## iter 110 value 80.439014
## iter 120 value 72.785177
## iter 130 value 66.413378
## iter 140 value 62.693453
## iter 150 value 57.223025
## iter 160 value 53.619572
## iter 170 value 52.749691
## iter 180 value 52.528716
## iter 190 value 52.460555
## iter 200 value 52.447945
## iter 210 value 50.333059
## iter 220 value 49.014225
## iter 230 value 43.186039
## iter 240 value 42.708835
## iter 250 value 42.654109
## iter 260 value 42.650460
## iter 270 value 42.582148
## iter 280 value 38.974166
## iter 290 value 37.790560
## iter 300 value 37.570192
## final value 37.570192
## stopped after 300 iterations
## # weights: 473
## initial value 643.563312
## iter 10 value 488.343331
## iter 20 value 363.270604
## iter 30 value 316.170299
## iter 40 value 274.729328
## iter 50 value 232.765985
## iter 60 value 206.638107
## iter 70 value 189.155670
## iter 80 value 185.189932
## iter 90 value 178.790735
## iter 100 value 174.996548
## iter 110 value 170.204051
## iter 120 value 167.582877
## iter 130 value 165.345513
## iter 140 value 162.174403
## iter 150 value 162.152682
## iter 160 value 162.143604
## iter 170 value 162.132637
## iter 180 value 159.470775
## iter 190 value 156.683325
## iter 200 value 156.655240
## iter 210 value 156.638026
## iter 220 value 152.231091
## iter 230 value 141.955839
## iter 240 value 138.758080
## iter 250 value 136.660830
## iter 260 value 135.651102
## iter 270 value 129.851547
## iter 280 value 126.921335
## iter 290 value 122.786398
## iter 300 value 119.759344
## final value 119.759344
## stopped after 300 iterations
## # weights: 473
## initial value 643.820360
## iter 10 value 609.202787
## iter 20 value 454.246175
## iter 30 value 402.025407
## iter 40 value 395.787746
## iter 50 value 386.506166
## iter 60 value 376.142068
## iter 70 value 374.335095
## iter 80 value 374.116502
## iter 90 value 370.606996
## iter 100 value 368.739329
## iter 110 value 368.702262
## iter 120 value 365.145546
## iter 130 value 363.274148
## iter 140 value 361.582592
## iter 150 value 359.518594
## iter 160 value 352.529007
## iter 170 value 348.948582
## iter 180 value 346.843675
## iter 190 value 346.519414
## iter 200 value 344.615367
## iter 210 value 344.605148
## iter 220 value 342.670355
## final value 342.667093
## converged
## # weights: 473
## initial value 636.861759
## iter 10 value 561.339679
## iter 20 value 510.179916
## iter 30 value 391.443184
## iter 40 value 230.892394
## iter 50 value 202.084231
## iter 60 value 173.022322
## iter 70 value 150.276472
## iter 80 value 133.063763
## iter 90 value 117.747689
## iter 100 value 105.409092
## iter 110 value 96.500705
## iter 120 value 84.521277
## iter 130 value 76.196329
## iter 140 value 69.105304
## iter 150 value 63.295172
## iter 160 value 58.981560
## iter 170 value 54.218542
## iter 180 value 52.760757
## iter 190 value 52.634315
## iter 200 value 52.582214
## iter 210 value 52.247598
## iter 220 value 48.814209
## iter 230 value 47.904919
## iter 240 value 47.808782
## iter 250 value 47.789572
## iter 260 value 47.785228
## iter 270 value 47.784083
## iter 280 value 47.783260
## iter 290 value 47.782927
## iter 300 value 47.782261
## final value 47.782261
## stopped after 300 iterations
## # weights: 473
## initial value 627.443966
## iter 10 value 530.907759
## iter 20 value 451.703137
## iter 30 value 395.038972
## iter 40 value 375.227136
## iter 50 value 348.397043
## iter 60 value 330.929195
## iter 70 value 318.050608
## iter 80 value 313.604374
## iter 90 value 311.766203
## iter 100 value 307.270566
## iter 110 value 302.918226
## iter 120 value 297.194110
## iter 130 value 293.579170
## iter 140 value 293.492585
## iter 150 value 293.447150
## iter 160 value 286.910304
## iter 170 value 284.966707
## iter 180 value 283.034706
## iter 190 value 281.289492
## iter 200 value 274.145531
## iter 210 value 268.766156
## iter 220 value 265.422050
## iter 230 value 263.604102
## iter 240 value 263.183042
## iter 250 value 261.446450
## iter 260 value 261.293883
## iter 270 value 259.521027
## iter 280 value 257.628335
## iter 290 value 257.513574
## iter 300 value 249.690971
## final value 249.690971
## stopped after 300 iterations
## # weights: 473
## initial value 655.471481
## iter 10 value 627.294783
## iter 20 value 625.005490
## iter 30 value 584.475504
## iter 40 value 512.403408
## iter 50 value 488.038660
## iter 60 value 477.564174
## iter 70 value 451.965640
## iter 80 value 444.618910
## iter 90 value 442.738581
## iter 100 value 441.488204
## iter 110 value 438.970343
## iter 120 value 437.899616
## iter 130 value 437.895693
## final value 437.895166
## converged
## # weights: 473
## initial value 700.145537
## iter 10 value 585.224240
## iter 20 value 384.416478
## iter 30 value 326.492830
## iter 40 value 299.857571
## iter 50 value 278.585744
## iter 60 value 256.140762
## iter 70 value 228.298157
## iter 80 value 215.929065
## iter 90 value 197.081646
## iter 100 value 166.482407
## iter 110 value 155.651856
## iter 120 value 146.132063
## iter 130 value 139.059892
## iter 140 value 112.615228
## iter 150 value 91.738408
## iter 160 value 83.588172
## iter 170 value 74.965824
## iter 180 value 71.082989
## iter 190 value 67.380679
## iter 200 value 63.587450
## iter 210 value 60.935148
## iter 220 value 54.773747
## iter 230 value 50.038151
## iter 240 value 48.591807
## iter 250 value 48.271739
## iter 260 value 48.227138
## iter 270 value 48.210989
## iter 280 value 48.207087
## iter 290 value 48.206186
## iter 300 value 48.206104
## final value 48.206104
## stopped after 300 iterations
## # weights: 473
## initial value 644.534150
## iter 10 value 526.051041
## iter 20 value 280.392550
## iter 30 value 251.639756
## iter 40 value 241.546613
## iter 50 value 239.809619
## iter 60 value 237.020090
## iter 70 value 236.960179
## iter 80 value 232.491046
## iter 90 value 226.403995
## iter 100 value 221.847090
## iter 110 value 221.737541
## iter 120 value 221.717447
## iter 130 value 219.369934
## iter 140 value 213.858591
## iter 150 value 206.666555
## iter 160 value 200.283149
## iter 170 value 200.194438
## iter 180 value 196.899475
## iter 190 value 196.877848
## iter 200 value 193.789755
## iter 210 value 193.492344
## iter 220 value 193.479866
## iter 230 value 193.462134
## iter 240 value 191.099620
## iter 250 value 184.129171
## iter 260 value 180.769983
## iter 270 value 178.197259
## iter 280 value 176.120889
## iter 290 value 175.496894
## iter 300 value 172.845053
## final value 172.845053
## stopped after 300 iterations
## # weights: 473
## initial value 649.744160
## iter 10 value 623.674043
## iter 20 value 593.680475
## iter 30 value 578.680080
## iter 40 value 562.142167
## iter 50 value 538.716011
## iter 60 value 511.225724
## iter 70 value 475.504609
## iter 80 value 432.637802
## iter 90 value 402.951295
## iter 100 value 372.872784
## iter 110 value 360.964788
## iter 120 value 357.831306
## iter 130 value 355.941273
## iter 140 value 354.611434
## iter 150 value 354.608441
## final value 354.608024
## converged
## # weights: 473
## initial value 664.505246
## iter 10 value 518.875452
## iter 20 value 346.630631
## iter 30 value 296.884059
## iter 40 value 247.695672
## iter 50 value 222.626773
## iter 60 value 207.878899
## iter 70 value 164.062632
## iter 80 value 143.837974
## iter 90 value 126.303658
## iter 100 value 111.116383
## iter 110 value 96.564458
## iter 120 value 89.257945
## iter 130 value 84.772980
## iter 140 value 76.454466
## iter 150 value 71.250516
## iter 160 value 69.272976
## iter 170 value 64.038420
## iter 180 value 57.943498
## iter 190 value 51.763190
## iter 200 value 50.962420
## iter 210 value 50.841783
## iter 220 value 50.826890
## iter 230 value 50.822128
## iter 240 value 50.820444
## iter 250 value 50.820111
## iter 260 value 50.820060
## iter 270 value 50.820044
## iter 280 value 50.541230
## iter 290 value 48.774371
## iter 300 value 46.862124
## final value 46.862124
## stopped after 300 iterations
## # weights: 473
## initial value 673.924381
## iter 10 value 628.003104
## iter 20 value 627.999654
## iter 30 value 626.535843
## iter 40 value 620.107305
## iter 50 value 596.323940
## iter 60 value 560.405364
## iter 70 value 519.070158
## iter 80 value 504.336635
## iter 90 value 491.965357
## iter 100 value 488.701984
## iter 110 value 487.274654
## iter 120 value 485.887700
## iter 130 value 483.339274
## iter 140 value 481.469674
## iter 150 value 481.349882
## iter 160 value 481.252797
## iter 170 value 472.358694
## iter 180 value 464.381676
## iter 190 value 461.216642
## iter 200 value 459.018835
## iter 210 value 457.180154
## iter 220 value 457.003106
## iter 230 value 456.011421
## iter 240 value 453.960892
## iter 250 value 452.819062
## iter 260 value 449.929042
## iter 270 value 446.547638
## iter 280 value 444.341505
## iter 290 value 443.039276
## iter 300 value 437.894587
## final value 437.894587
## stopped after 300 iterations
## # weights: 473
## initial value 627.032751
## iter 10 value 599.502820
## iter 20 value 565.179851
## iter 30 value 426.436449
## iter 40 value 204.245684
## iter 50 value 168.849143
## iter 60 value 162.507962
## iter 70 value 159.374947
## iter 80 value 156.520302
## iter 90 value 150.433288
## iter 100 value 150.037786
## iter 110 value 150.025945
## iter 120 value 147.259964
## iter 130 value 142.375930
## iter 140 value 140.453260
## iter 150 value 137.579906
## iter 160 value 133.677565
## iter 170 value 133.566927
## iter 180 value 133.563392
## iter 190 value 133.561971
## iter 200 value 133.560841
## iter 210 value 133.559738
## iter 220 value 133.559115
## iter 230 value 133.558673
## iter 240 value 130.627406
## iter 250 value 130.619691
## iter 260 value 127.676048
## iter 270 value 127.642246
## iter 280 value 127.640976
## iter 290 value 127.640704
## iter 300 value 127.640442
## final value 127.640442
## stopped after 300 iterations
## # weights: 473
## initial value 633.769190
## iter 10 value 557.210959
## iter 20 value 454.492255
## iter 30 value 342.745224
## iter 40 value 266.497181
## iter 50 value 241.072792
## iter 60 value 203.780144
## iter 70 value 168.300523
## iter 80 value 154.473158
## iter 90 value 126.856444
## iter 100 value 101.993180
## iter 110 value 90.544787
## iter 120 value 83.987635
## iter 130 value 77.960294
## iter 140 value 69.651575
## iter 150 value 60.659467
## iter 160 value 51.963078
## iter 170 value 47.647030
## iter 180 value 37.582392
## iter 190 value 33.476188
## iter 200 value 32.505155
## iter 210 value 32.397482
## iter 220 value 32.360079
## iter 230 value 32.338539
## iter 240 value 32.331188
## iter 250 value 32.328870
## iter 260 value 32.326794
## iter 270 value 32.326129
## iter 280 value 32.326002
## final value 32.325994
## converged
## # weights: 473
## initial value 639.995544
## iter 10 value 598.506144
## iter 20 value 536.176102
## iter 30 value 401.187178
## iter 40 value 325.591216
## iter 50 value 312.473514
## iter 60 value 305.796676
## iter 70 value 282.156071
## iter 80 value 269.562432
## iter 90 value 253.139289
## iter 100 value 232.183874
## iter 110 value 228.324226
## iter 120 value 222.169200
## iter 130 value 214.292186
## iter 140 value 210.896734
## iter 150 value 208.381153
## iter 160 value 205.881231
## iter 170 value 203.155104
## iter 180 value 199.175344
## iter 190 value 195.954090
## iter 200 value 195.934559
## iter 210 value 190.588007
## iter 220 value 190.127233
## iter 230 value 190.116846
## iter 240 value 190.105896
## iter 250 value 190.067542
## iter 260 value 184.777645
## iter 270 value 182.274101
## iter 280 value 182.258374
## iter 290 value 182.252554
## iter 300 value 182.245508
## final value 182.245508
## stopped after 300 iterations
## # weights: 473
## initial value 652.101941
## iter 10 value 511.127594
## iter 20 value 358.828605
## iter 30 value 287.226522
## iter 40 value 266.528958
## iter 50 value 258.448691
## iter 60 value 255.959355
## iter 70 value 253.483612
## iter 80 value 247.140527
## iter 90 value 245.752770
## iter 100 value 243.393483
## iter 110 value 243.361402
## iter 120 value 243.359284
## iter 130 value 243.337507
## iter 140 value 239.074649
## iter 150 value 238.522155
## iter 160 value 236.139270
## iter 170 value 230.502237
## iter 180 value 228.056159
## iter 190 value 228.053447
## iter 200 value 228.052018
## iter 210 value 228.051554
## iter 220 value 228.051385
## final value 228.051247
## converged
## # weights: 473
## initial value 647.510802
## iter 10 value 519.345587
## iter 20 value 405.388945
## iter 30 value 313.897655
## iter 40 value 267.473497
## iter 50 value 227.378106
## iter 60 value 184.068481
## iter 70 value 153.029826
## iter 80 value 135.561410
## iter 90 value 112.787308
## iter 100 value 102.731218
## iter 110 value 92.647338
## iter 120 value 81.182079
## iter 130 value 73.718841
## iter 140 value 67.271472
## iter 150 value 64.146673
## iter 160 value 59.023159
## iter 170 value 49.334804
## iter 180 value 48.483691
## iter 190 value 48.359963
## iter 200 value 48.340827
## iter 210 value 48.335153
## iter 220 value 48.331470
## iter 230 value 48.330076
## iter 240 value 48.329715
## final value 48.329692
## converged
## # weights: 473
## initial value 647.628277
## iter 10 value 590.413573
## iter 20 value 525.948651
## iter 30 value 444.549593
## iter 40 value 396.898786
## iter 50 value 335.038400
## iter 60 value 289.080625
## iter 70 value 278.912266
## iter 80 value 271.974953
## iter 90 value 262.945805
## iter 100 value 257.000732
## iter 110 value 251.265109
## iter 120 value 246.650135
## iter 130 value 244.621835
## iter 140 value 244.575203
## iter 150 value 242.958087
## iter 160 value 240.506209
## iter 170 value 238.640636
## iter 180 value 238.431937
## iter 190 value 238.416554
## iter 200 value 238.403842
## iter 210 value 234.889644
## iter 220 value 232.831068
## iter 230 value 232.796014
## iter 240 value 232.788232
## iter 250 value 229.073677
## iter 260 value 225.119426
## iter 270 value 222.893658
## iter 280 value 222.832082
## iter 290 value 220.780374
## iter 300 value 220.682810
## final value 220.682810
## stopped after 300 iterations
## # weights: 473
## initial value 675.146692
## iter 10 value 574.156015
## iter 20 value 469.288291
## iter 30 value 345.777929
## iter 40 value 256.025510
## iter 50 value 235.537638
## iter 60 value 212.777389
## iter 70 value 198.262273
## iter 80 value 190.321773
## iter 90 value 177.786362
## iter 100 value 170.884833
## iter 110 value 160.858804
## iter 120 value 160.310359
## iter 130 value 157.026031
## iter 140 value 153.768924
## iter 150 value 151.857819
## iter 160 value 148.165332
## iter 170 value 148.147277
## iter 180 value 148.139041
## iter 190 value 148.129744
## iter 200 value 145.254530
## iter 210 value 145.245319
## iter 220 value 145.243915
## iter 230 value 142.324364
## iter 240 value 139.381200
## iter 250 value 137.133768
## iter 260 value 136.351811
## iter 270 value 136.348054
## iter 280 value 133.572502
## iter 290 value 133.298068
## iter 300 value 133.296252
## final value 133.296252
## stopped after 300 iterations
## # weights: 473
## initial value 664.979798
## iter 10 value 583.200292
## iter 20 value 434.945452
## iter 30 value 336.670111
## iter 40 value 277.852625
## iter 50 value 237.204125
## iter 60 value 185.142651
## iter 70 value 156.726196
## iter 80 value 138.852005
## iter 90 value 116.186548
## iter 100 value 101.753252
## iter 110 value 94.731028
## iter 120 value 86.656265
## iter 130 value 80.574120
## iter 140 value 72.367725
## iter 150 value 63.498071
## iter 160 value 59.873019
## iter 170 value 56.442594
## iter 180 value 48.940800
## iter 190 value 43.782274
## iter 200 value 42.907910
## iter 210 value 42.721893
## iter 220 value 42.591449
## iter 230 value 42.438273
## iter 240 value 37.437771
## iter 250 value 37.185127
## iter 260 value 37.078272
## iter 270 value 37.063514
## iter 280 value 37.061277
## iter 290 value 37.060799
## iter 300 value 37.060724
## final value 37.060724
## stopped after 300 iterations
## # weights: 473
## initial value 651.726908
## iter 10 value 524.094374
## iter 20 value 426.717974
## iter 30 value 353.129752
## iter 40 value 308.791719
## iter 50 value 297.570196
## iter 60 value 294.592366
## iter 70 value 290.138155
## iter 80 value 287.107951
## iter 90 value 285.836698
## iter 100 value 281.924734
## iter 110 value 274.724619
## iter 120 value 265.123926
## iter 130 value 264.597135
## iter 140 value 260.313255
## iter 150 value 260.107523
## iter 160 value 260.070642
## iter 170 value 253.217492
## iter 180 value 250.918839
## iter 190 value 250.868916
## iter 200 value 248.537287
## iter 210 value 245.936651
## iter 220 value 243.285836
## iter 230 value 243.267877
## iter 240 value 243.240279
## iter 250 value 241.876694
## iter 260 value 239.001810
## iter 270 value 238.433576
## iter 280 value 238.421926
## iter 290 value 235.780335
## iter 300 value 235.718417
## final value 235.718417
## stopped after 300 iterations
## # weights: 473
## initial value 666.972817
## iter 10 value 606.335742
## iter 20 value 464.759691
## iter 30 value 386.400368
## iter 40 value 373.962235
## iter 50 value 361.127333
## iter 60 value 348.630763
## iter 70 value 332.157196
## iter 80 value 317.003341
## iter 90 value 303.510596
## iter 100 value 296.716951
## iter 110 value 293.938989
## iter 120 value 290.892884
## iter 130 value 289.249898
## iter 140 value 285.012997
## iter 150 value 284.819652
## iter 160 value 283.150499
## iter 170 value 281.468779
## iter 180 value 279.814735
## iter 190 value 279.788808
## iter 200 value 278.455619
## iter 210 value 274.855485
## iter 220 value 274.687337
## iter 230 value 274.685391
## iter 240 value 274.684708
## iter 250 value 274.684567
## final value 274.684218
## converged
## # weights: 473
## initial value 669.491350
## iter 10 value 594.649392
## iter 20 value 362.655819
## iter 30 value 275.537719
## iter 40 value 236.091449
## iter 50 value 194.384914
## iter 60 value 171.194288
## iter 70 value 152.095256
## iter 80 value 134.815935
## iter 90 value 123.567059
## iter 100 value 115.809555
## iter 110 value 109.325808
## iter 120 value 98.433835
## iter 130 value 91.663292
## iter 140 value 86.134287
## iter 150 value 80.133652
## iter 160 value 77.821870
## iter 170 value 73.789848
## iter 180 value 71.860547
## iter 190 value 71.455089
## iter 200 value 71.411838
## iter 210 value 63.156668
## iter 220 value 62.358682
## iter 230 value 58.281431
## iter 240 value 54.473328
## iter 250 value 53.596060
## iter 260 value 48.983847
## iter 270 value 48.358315
## iter 280 value 48.301440
## iter 290 value 48.289298
## iter 300 value 48.287235
## final value 48.287235
## stopped after 300 iterations
## # weights: 473
## initial value 672.220291
## iter 10 value 623.288911
## iter 20 value 608.214540
## iter 30 value 570.210417
## iter 40 value 552.036212
## iter 50 value 537.754477
## iter 60 value 511.507771
## iter 70 value 478.820253
## iter 80 value 454.918148
## iter 90 value 420.369255
## iter 100 value 379.486086
## iter 110 value 338.261213
## iter 120 value 317.577493
## iter 130 value 311.381189
## iter 140 value 309.734200
## iter 150 value 306.700651
## iter 160 value 306.587305
## iter 170 value 304.899248
## iter 180 value 300.688509
## iter 190 value 298.708111
## iter 200 value 298.516846
## iter 210 value 290.903149
## iter 220 value 285.709822
## iter 230 value 285.633532
## iter 240 value 280.663856
## iter 250 value 278.998298
## iter 260 value 275.617178
## iter 270 value 275.556259
## iter 280 value 270.457942
## iter 290 value 268.674318
## iter 300 value 266.929692
## final value 266.929692
## stopped after 300 iterations
## # weights: 473
## initial value 667.519018
## iter 10 value 627.786584
## iter 20 value 620.233390
## iter 30 value 507.563219
## iter 40 value 426.641344
## iter 50 value 394.555799
## iter 60 value 388.958758
## iter 70 value 387.471766
## iter 80 value 386.004111
## iter 90 value 383.959515
## iter 100 value 381.687521
## iter 110 value 381.684318
## final value 381.683823
## converged
## # weights: 473
## initial value 698.282346
## iter 10 value 572.796349
## iter 20 value 473.932806
## iter 30 value 392.065573
## iter 40 value 344.101248
## iter 50 value 310.641974
## iter 60 value 284.802221
## iter 70 value 266.425320
## iter 80 value 237.828282
## iter 90 value 213.063253
## iter 100 value 181.796177
## iter 110 value 160.454197
## iter 120 value 139.799439
## iter 130 value 118.649295
## iter 140 value 99.735545
## iter 150 value 87.105357
## iter 160 value 74.849258
## iter 170 value 69.379267
## iter 180 value 68.071326
## iter 190 value 67.609955
## iter 200 value 64.742358
## iter 210 value 63.513479
## iter 220 value 61.327093
## iter 230 value 59.405788
## iter 240 value 58.691959
## iter 250 value 58.593126
## iter 260 value 58.583612
## iter 270 value 58.579880
## iter 280 value 58.579091
## iter 290 value 58.578959
## final value 58.578948
## converged
## # weights: 473
## initial value 648.776523
## iter 10 value 551.622295
## iter 20 value 416.927410
## iter 30 value 333.268097
## iter 40 value 272.629267
## iter 50 value 262.031600
## iter 60 value 256.173548
## iter 70 value 251.268485
## iter 80 value 246.740702
## iter 90 value 242.317764
## iter 100 value 237.480867
## iter 110 value 235.814026
## iter 120 value 235.038808
## iter 130 value 232.660965
## iter 140 value 230.239682
## iter 150 value 227.895081
## iter 160 value 227.430456
## iter 170 value 225.326287
## iter 180 value 220.067624
## iter 190 value 220.024878
## iter 200 value 218.730589
## iter 210 value 217.492814
## iter 220 value 207.369725
## iter 230 value 204.923041
## iter 240 value 201.864409
## iter 250 value 199.353220
## iter 260 value 199.101539
## iter 270 value 199.092906
## iter 280 value 196.339857
## iter 290 value 192.957332
## iter 300 value 190.851864
## final value 190.851864
## stopped after 300 iterations
## # weights: 473
## initial value 674.700244
## iter 10 value 576.503402
## iter 20 value 434.332829
## iter 30 value 374.340327
## iter 40 value 353.828507
## iter 50 value 351.172631
## iter 60 value 332.595628
## iter 70 value 298.739629
## iter 80 value 280.649546
## iter 90 value 276.370380
## iter 100 value 267.949778
## iter 110 value 259.247941
## iter 120 value 251.133923
## iter 130 value 250.483776
## iter 140 value 245.570146
## iter 150 value 243.246950
## iter 160 value 243.199629
## iter 170 value 243.195806
## iter 180 value 240.927553
## iter 190 value 240.921770
## iter 200 value 240.920661
## final value 240.919918
## converged
## # weights: 473
## initial value 656.096878
## iter 10 value 558.057210
## iter 20 value 483.515629
## iter 30 value 395.477216
## iter 40 value 334.868934
## iter 50 value 278.559382
## iter 60 value 247.119561
## iter 70 value 199.155845
## iter 80 value 175.592213
## iter 90 value 159.238354
## iter 100 value 151.530689
## iter 110 value 145.792134
## iter 120 value 129.822986
## iter 130 value 116.213107
## iter 140 value 104.647250
## iter 150 value 99.388499
## iter 160 value 95.933499
## iter 170 value 94.855391
## iter 180 value 93.480691
## iter 190 value 89.105798
## iter 200 value 76.821678
## iter 210 value 68.114590
## iter 220 value 63.453005
## iter 230 value 61.039193
## iter 240 value 58.872573
## iter 250 value 58.146478
## iter 260 value 54.746199
## iter 270 value 49.679141
## iter 280 value 46.497208
## iter 290 value 39.555858
## iter 300 value 38.626319
## final value 38.626319
## stopped after 300 iterations
## # weights: 473
## initial value 642.518317
## iter 10 value 471.052562
## iter 20 value 330.973426
## iter 30 value 287.449645
## iter 40 value 276.028075
## iter 50 value 266.943618
## iter 60 value 258.626113
## iter 70 value 252.037731
## iter 80 value 249.013956
## iter 90 value 248.899693
## iter 100 value 243.956431
## iter 110 value 243.930976
## iter 120 value 241.249566
## iter 130 value 238.379139
## iter 140 value 236.077474
## iter 150 value 235.506847
## iter 160 value 233.104809
## iter 170 value 233.061387
## iter 180 value 230.756467
## iter 190 value 230.734551
## iter 200 value 227.913019
## iter 210 value 227.777072
## iter 220 value 225.868853
## iter 230 value 220.788370
## iter 240 value 217.889033
## iter 250 value 217.665441
## iter 260 value 217.589299
## iter 270 value 215.958654
## iter 280 value 212.507355
## iter 290 value 210.046487
## iter 300 value 209.032093
## final value 209.032093
## stopped after 300 iterations
## # weights: 473
## initial value 685.155893
## iter 10 value 623.919452
## iter 20 value 621.731988
## iter 30 value 621.725725
## final value 621.725711
## converged
## # weights: 473
## initial value 690.544687
## iter 10 value 625.220558
## iter 20 value 603.891191
## iter 30 value 506.686977
## iter 40 value 410.968323
## iter 50 value 346.032730
## iter 60 value 292.448077
## iter 70 value 251.663227
## iter 80 value 225.567896
## iter 90 value 203.832741
## iter 100 value 174.080462
## iter 110 value 145.381967
## iter 120 value 131.515542
## iter 130 value 115.402378
## iter 140 value 105.624743
## iter 150 value 97.408618
## iter 160 value 86.485342
## iter 170 value 81.131064
## iter 180 value 73.689238
## iter 190 value 71.101888
## iter 200 value 64.395874
## iter 210 value 58.000734
## iter 220 value 53.092822
## iter 230 value 52.318758
## iter 240 value 52.245430
## iter 250 value 52.233174
## iter 260 value 52.225748
## iter 270 value 52.223120
## iter 280 value 52.222756
## iter 290 value 52.222733
## final value 52.222732
## converged
## # weights: 473
## initial value 680.344393
## iter 10 value 587.190464
## iter 20 value 474.352898
## iter 30 value 426.553484
## iter 40 value 414.191756
## iter 50 value 397.224484
## iter 60 value 385.935118
## iter 70 value 383.868452
## iter 80 value 377.258927
## iter 90 value 374.770765
## iter 100 value 372.417587
## iter 110 value 371.039922
## final value 370.868832
## converged
## # weights: 473
## initial value 639.181740
## iter 10 value 529.984261
## iter 20 value 379.401093
## iter 30 value 342.563068
## iter 40 value 334.986624
## iter 50 value 327.389620
## iter 60 value 324.200638
## iter 70 value 323.575043
## iter 80 value 318.462203
## iter 90 value 318.102385
## iter 100 value 317.681663
## iter 110 value 311.050573
## iter 120 value 308.693425
## iter 130 value 304.686663
## iter 140 value 302.888967
## iter 150 value 302.824550
## iter 160 value 300.922674
## iter 170 value 300.915248
## iter 180 value 299.028455
## iter 190 value 298.942004
## iter 200 value 298.941323
## iter 210 value 298.219658
## iter 220 value 296.508321
## iter 230 value 296.504923
## iter 240 value 294.071818
## iter 250 value 294.044047
## iter 260 value 294.043236
## iter 270 value 291.550974
## iter 280 value 291.549554
## final value 291.549369
## converged
## # weights: 473
## initial value 665.445163
## iter 10 value 586.516651
## iter 20 value 455.956988
## iter 30 value 388.035197
## iter 40 value 339.663107
## iter 50 value 300.339428
## iter 60 value 274.811107
## iter 70 value 243.819071
## iter 80 value 210.970479
## iter 90 value 193.962059
## iter 100 value 165.558039
## iter 110 value 137.091939
## iter 120 value 124.399080
## iter 130 value 109.122136
## iter 140 value 97.080078
## iter 150 value 86.757949
## iter 160 value 79.465554
## iter 170 value 76.431649
## iter 180 value 74.457276
## iter 190 value 68.171639
## iter 200 value 64.587784
## iter 210 value 62.443691
## iter 220 value 58.262931
## iter 230 value 57.771547
## iter 240 value 57.710836
## iter 250 value 57.686815
## iter 260 value 57.660345
## iter 270 value 57.653600
## iter 280 value 57.652586
## iter 290 value 57.652532
## final value 57.652529
## converged
## # weights: 473
## initial value 676.096985
## iter 10 value 625.038608
## iter 20 value 595.121193
## iter 30 value 512.408480
## iter 40 value 458.319714
## iter 50 value 414.537534
## iter 60 value 411.186900
## iter 70 value 401.789644
## iter 80 value 399.905471
## iter 90 value 396.499931
## iter 100 value 391.699462
## iter 110 value 384.711889
## iter 120 value 379.280766
## iter 130 value 375.102803
## iter 140 value 370.968833
## iter 150 value 366.951061
## iter 160 value 365.651630
## iter 170 value 364.070555
## iter 180 value 362.649291
## iter 190 value 362.588170
## iter 200 value 354.927304
## iter 210 value 332.825321
## iter 220 value 307.454614
## iter 230 value 295.981921
## iter 240 value 290.198350
## iter 250 value 286.884386
## iter 260 value 283.324657
## iter 270 value 283.275311
## iter 280 value 281.457023
## iter 290 value 267.815906
## iter 300 value 264.908723
## final value 264.908723
## stopped after 300 iterations
## # weights: 473
## initial value 660.918139
## iter 10 value 627.981852
## iter 20 value 612.980968
## iter 30 value 557.269081
## iter 40 value 547.941326
## iter 50 value 535.989751
## iter 60 value 512.115711
## iter 70 value 488.254241
## iter 80 value 488.187876
## iter 80 value 488.187875
## final value 488.187875
## converged
## # weights: 473
## initial value 727.154444
## iter 10 value 628.145637
## iter 20 value 552.111133
## iter 30 value 493.437344
## iter 40 value 455.575265
## iter 50 value 438.955282
## iter 60 value 422.487308
## iter 70 value 383.096549
## iter 80 value 274.030359
## iter 90 value 226.568060
## iter 100 value 193.648468
## iter 110 value 173.567433
## iter 120 value 158.249526
## iter 130 value 140.958943
## iter 140 value 121.392487
## iter 150 value 105.327389
## iter 160 value 99.258691
## iter 170 value 85.202132
## iter 180 value 76.328891
## iter 190 value 73.210846
## iter 200 value 69.401069
## iter 210 value 62.722943
## iter 220 value 58.968766
## iter 230 value 58.081860
## iter 240 value 57.871439
## iter 250 value 57.752087
## iter 260 value 57.679879
## iter 270 value 57.572310
## iter 280 value 57.539074
## iter 290 value 57.520151
## iter 300 value 57.506797
## final value 57.506797
## stopped after 300 iterations
## # weights: 473
## initial value 627.044011
## iter 10 value 578.828423
## iter 20 value 547.125217
## iter 30 value 491.245119
## iter 40 value 391.504241
## iter 50 value 275.605778
## iter 60 value 236.093794
## iter 70 value 209.286956
## iter 80 value 194.035912
## iter 90 value 187.384522
## iter 100 value 179.404107
## iter 110 value 169.909598
## iter 120 value 164.564547
## iter 130 value 160.255123
## iter 140 value 160.074403
## iter 150 value 160.058723
## iter 160 value 160.053341
## iter 170 value 160.049267
## iter 180 value 160.044665
## iter 190 value 157.503457
## iter 200 value 156.682818
## iter 210 value 153.352371
## iter 220 value 153.248576
## iter 230 value 153.217612
## iter 240 value 150.288246
## iter 250 value 150.283385
## iter 260 value 147.591142
## iter 270 value 146.771498
## iter 280 value 146.765043
## iter 290 value 146.762693
## iter 300 value 146.760771
## final value 146.760771
## stopped after 300 iterations
## # weights: 473
## initial value 633.638306
## iter 10 value 586.233435
## iter 20 value 472.023607
## iter 30 value 330.876470
## iter 40 value 262.401122
## iter 50 value 243.636830
## iter 60 value 222.592302
## iter 70 value 208.776188
## iter 80 value 194.678531
## iter 90 value 191.683795
## iter 100 value 191.616856
## iter 110 value 191.597876
## iter 120 value 191.588735
## iter 130 value 190.104950
## iter 140 value 185.992247
## iter 150 value 184.709940
## iter 160 value 184.695380
## iter 170 value 184.694080
## iter 180 value 184.693284
## iter 190 value 184.692737
## iter 200 value 184.692231
## iter 210 value 184.691939
## final value 184.691899
## converged
## # weights: 473
## initial value 640.222723
## iter 10 value 588.453274
## iter 20 value 380.207698
## iter 30 value 328.636292
## iter 40 value 272.899369
## iter 50 value 247.442062
## iter 60 value 223.772236
## iter 70 value 191.307427
## iter 80 value 178.079566
## iter 90 value 167.341570
## iter 100 value 152.154258
## iter 110 value 140.958607
## iter 120 value 131.181886
## iter 130 value 124.696120
## iter 140 value 109.484026
## iter 150 value 103.434730
## iter 160 value 95.833837
## iter 170 value 86.201666
## iter 180 value 79.818780
## iter 190 value 75.095358
## iter 200 value 68.980913
## iter 210 value 63.374466
## iter 220 value 59.088399
## iter 230 value 56.484217
## iter 240 value 55.754189
## iter 250 value 55.629232
## iter 260 value 51.799163
## iter 270 value 47.428526
## iter 280 value 47.063026
## iter 290 value 43.002189
## iter 300 value 42.575405
## final value 42.575405
## stopped after 300 iterations
## # weights: 473
## initial value 628.386901
## iter 10 value 424.431888
## iter 20 value 295.906072
## iter 30 value 264.787555
## iter 40 value 261.963514
## iter 50 value 259.996430
## iter 60 value 256.908843
## iter 70 value 247.672933
## iter 80 value 243.855674
## iter 90 value 235.229195
## iter 100 value 230.956184
## iter 110 value 228.594399
## iter 120 value 227.227541
## iter 130 value 220.752232
## iter 140 value 214.096227
## iter 150 value 212.172104
## iter 160 value 208.495408
## iter 170 value 208.323400
## iter 180 value 206.176033
## iter 190 value 203.977309
## iter 200 value 203.857764
## iter 210 value 197.140385
## iter 220 value 197.001370
## iter 230 value 196.976900
## iter 240 value 196.947891
## iter 250 value 196.921688
## iter 260 value 196.316130
## iter 270 value 194.567500
## iter 280 value 192.236823
## iter 290 value 190.363479
## iter 300 value 185.172640
## final value 185.172640
## stopped after 300 iterations
## # weights: 473
## initial value 634.851107
## iter 10 value 524.818511
## iter 20 value 398.233706
## iter 30 value 307.529032
## iter 40 value 271.659620
## iter 50 value 262.411268
## iter 60 value 258.835380
## iter 70 value 254.846160
## iter 80 value 254.210271
## iter 90 value 251.976266
## iter 100 value 249.245334
## iter 110 value 245.064818
## iter 120 value 241.937870
## iter 130 value 239.183437
## iter 140 value 235.431433
## iter 150 value 234.473966
## iter 160 value 232.496209
## iter 170 value 232.089463
## iter 180 value 232.086578
## iter 190 value 232.084442
## iter 200 value 232.082808
## iter 210 value 232.081741
## iter 220 value 232.081409
## iter 230 value 229.697937
## iter 240 value 229.687312
## final value 229.686846
## converged
## # weights: 473
## initial value 663.279412
## iter 10 value 467.322609
## iter 20 value 345.995653
## iter 30 value 290.596238
## iter 40 value 250.395945
## iter 50 value 207.896820
## iter 60 value 178.208332
## iter 70 value 155.001050
## iter 80 value 140.626069
## iter 90 value 117.868027
## iter 100 value 101.948628
## iter 110 value 93.111270
## iter 120 value 83.405514
## iter 130 value 77.956726
## iter 140 value 69.585030
## iter 150 value 63.365523
## iter 160 value 58.476618
## iter 170 value 55.124237
## iter 180 value 50.185959
## iter 190 value 49.064379
## iter 200 value 48.645018
## iter 210 value 48.462443
## iter 220 value 44.021378
## iter 230 value 43.397780
## iter 240 value 43.306967
## iter 250 value 43.293939
## iter 260 value 43.292206
## iter 270 value 43.291783
## iter 280 value 43.291699
## final value 43.291681
## converged
## # weights: 473
## initial value 675.167474
## iter 10 value 573.491350
## iter 20 value 468.885365
## iter 30 value 419.666558
## iter 40 value 402.737037
## iter 50 value 394.430548
## iter 60 value 386.054730
## iter 70 value 382.940577
## iter 80 value 382.345353
## iter 90 value 377.906161
## iter 100 value 375.923406
## iter 110 value 375.866350
## iter 120 value 370.624627
## iter 130 value 364.069993
## iter 140 value 362.455414
## iter 150 value 359.552449
## iter 160 value 356.025465
## iter 170 value 354.031398
## iter 180 value 352.028884
## iter 190 value 347.973237
## iter 200 value 347.700195
## iter 210 value 347.131506
## iter 220 value 345.921476
## iter 230 value 344.290610
## iter 240 value 343.733730
## iter 250 value 337.598258
## iter 260 value 336.210840
## iter 270 value 334.871363
## iter 280 value 334.368095
## iter 290 value 332.550027
## iter 300 value 330.566674
## final value 330.566674
## stopped after 300 iterations
## # weights: 473
## initial value 689.705988
## iter 10 value 627.285996
## iter 20 value 619.945478
## iter 30 value 598.031670
## iter 40 value 543.160518
## iter 50 value 535.343090
## iter 60 value 530.889530
## iter 70 value 530.007739
## iter 80 value 529.984313
## iter 90 value 525.173863
## iter 100 value 519.649890
## iter 110 value 499.790469
## iter 120 value 462.953627
## iter 130 value 400.437013
## iter 140 value 393.449110
## iter 150 value 381.890360
## iter 160 value 369.499909
## iter 170 value 366.383233
## iter 180 value 363.625408
## iter 190 value 363.601775
## iter 200 value 363.600607
## final value 363.600447
## converged
## # weights: 473
## initial value 635.609364
## iter 10 value 568.264058
## iter 20 value 427.725769
## iter 30 value 369.673020
## iter 40 value 343.580445
## iter 50 value 321.428048
## iter 60 value 300.391094
## iter 70 value 279.814329
## iter 80 value 267.867399
## iter 90 value 253.929448
## iter 100 value 235.422703
## iter 110 value 216.738808
## iter 120 value 208.324163
## iter 130 value 197.568573
## iter 140 value 183.638512
## iter 150 value 171.103581
## iter 160 value 161.053176
## iter 170 value 141.045746
## iter 180 value 128.641004
## iter 190 value 118.350422
## iter 200 value 100.827849
## iter 210 value 89.684235
## iter 220 value 82.978030
## iter 230 value 77.620418
## iter 240 value 64.802824
## iter 250 value 54.318034
## iter 260 value 50.876468
## iter 270 value 46.242087
## iter 280 value 42.873263
## iter 290 value 42.487799
## iter 300 value 42.347877
## final value 42.347877
## stopped after 300 iterations
## # weights: 473
## initial value 670.126188
## iter 10 value 556.152645
## iter 20 value 499.932137
## iter 30 value 476.159685
## iter 40 value 465.144172
## iter 50 value 457.127631
## iter 60 value 444.937829
## iter 70 value 431.882067
## iter 80 value 427.969295
## iter 90 value 421.999850
## iter 100 value 414.214935
## iter 110 value 412.744012
## iter 120 value 411.126011
## iter 130 value 410.135604
## iter 140 value 408.006447
## iter 150 value 407.779423
## iter 160 value 403.069978
## iter 170 value 401.487091
## iter 180 value 400.021680
## iter 190 value 396.637178
## iter 200 value 391.387610
## iter 210 value 383.217941
## iter 220 value 378.147441
## iter 230 value 375.862755
## iter 240 value 370.032483
## iter 250 value 358.563372
## iter 260 value 341.534338
## iter 270 value 318.117818
## iter 280 value 312.926997
## iter 290 value 310.644022
## iter 300 value 306.615042
## final value 306.615042
## stopped after 300 iterations
## # weights: 473
## initial value 628.726804
## iter 10 value 545.276950
## iter 20 value 496.171017
## iter 30 value 396.074283
## iter 40 value 319.220447
## iter 50 value 305.644266
## iter 60 value 301.162185
## iter 70 value 295.117380
## iter 80 value 293.365245
## iter 90 value 291.022775
## iter 100 value 290.924011
## iter 110 value 287.210626
## iter 120 value 287.161883
## iter 130 value 285.317600
## iter 140 value 285.297932
## iter 150 value 282.395163
## iter 160 value 281.383185
## iter 170 value 274.720060
## iter 180 value 272.775412
## iter 190 value 272.761326
## iter 200 value 270.817890
## iter 210 value 270.798413
## iter 220 value 270.796819
## iter 230 value 267.820821
## iter 240 value 265.829472
## iter 250 value 265.824559
## iter 260 value 265.823887
## iter 270 value 265.823425
## iter 280 value 265.822678
## iter 290 value 262.820739
## iter 300 value 262.767855
## final value 262.767855
## stopped after 300 iterations
## # weights: 473
## initial value 644.278142
## iter 10 value 514.462826
## iter 20 value 406.604255
## iter 30 value 324.047215
## iter 40 value 271.648286
## iter 50 value 228.627304
## iter 60 value 195.441443
## iter 70 value 171.605262
## iter 80 value 152.838093
## iter 90 value 141.790340
## iter 100 value 118.647019
## iter 110 value 99.631080
## iter 120 value 91.796764
## iter 130 value 79.411004
## iter 140 value 66.989456
## iter 150 value 59.883056
## iter 160 value 52.839989
## iter 170 value 51.327064
## iter 180 value 50.483864
## iter 190 value 48.583618
## iter 200 value 47.236672
## iter 210 value 46.828370
## iter 220 value 46.784064
## iter 230 value 46.772995
## iter 240 value 46.770326
## iter 250 value 46.769613
## iter 260 value 46.769350
## iter 270 value 46.769311
## final value 46.769308
## converged
## # weights: 473
## initial value 662.317262
## iter 10 value 613.726727
## iter 20 value 572.624061
## iter 30 value 475.029464
## iter 40 value 359.671063
## iter 50 value 330.310105
## iter 60 value 320.381676
## iter 70 value 315.597905
## iter 80 value 308.122304
## iter 90 value 302.963601
## iter 100 value 298.588565
## iter 110 value 298.298108
## iter 120 value 296.414529
## iter 130 value 291.983375
## iter 140 value 291.841063
## iter 150 value 286.282023
## iter 160 value 285.251021
## iter 170 value 278.436486
## iter 180 value 276.633189
## iter 190 value 272.538378
## iter 200 value 270.603464
## iter 210 value 265.707132
## iter 220 value 263.551986
## iter 230 value 261.404306
## iter 240 value 255.285329
## iter 250 value 250.579167
## iter 260 value 248.369138
## iter 270 value 248.279516
## iter 280 value 246.065619
## iter 290 value 246.057204
## iter 300 value 246.047966
## final value 246.047966
## stopped after 300 iterations
## # weights: 473
## initial value 648.529318
## iter 10 value 494.572729
## iter 20 value 451.751377
## iter 30 value 432.477916
## iter 40 value 424.833373
## iter 50 value 421.483764
## iter 60 value 417.729383
## iter 70 value 416.443621
## iter 80 value 414.845784
## iter 90 value 413.635943
## iter 100 value 411.844541
## iter 110 value 411.838862
## iter 120 value 410.331356
## iter 130 value 408.756014
## iter 140 value 408.624875
## iter 150 value 406.938400
## iter 160 value 406.909638
## final value 406.909166
## converged
## # weights: 473
## initial value 666.433421
## iter 10 value 588.443706
## iter 20 value 483.477420
## iter 30 value 388.001551
## iter 40 value 344.130941
## iter 50 value 299.252479
## iter 60 value 263.306311
## iter 70 value 230.925210
## iter 80 value 208.399022
## iter 90 value 189.888722
## iter 100 value 172.957325
## iter 110 value 156.471953
## iter 120 value 145.195982
## iter 130 value 131.781037
## iter 140 value 116.280633
## iter 150 value 108.071690
## iter 160 value 98.448473
## iter 170 value 88.651758
## iter 180 value 74.844234
## iter 190 value 70.986885
## iter 200 value 65.269776
## iter 210 value 61.619245
## iter 220 value 54.916481
## iter 230 value 53.458345
## iter 240 value 49.691846
## iter 250 value 49.236604
## iter 260 value 47.815606
## iter 270 value 40.643478
## iter 280 value 38.909837
## iter 290 value 38.483108
## iter 300 value 38.414502
## final value 38.414502
## stopped after 300 iterations
## # weights: 473
## initial value 647.273054
## iter 10 value 611.365924
## iter 20 value 579.271713
## iter 30 value 435.903297
## iter 40 value 383.554726
## iter 50 value 369.518091
## iter 60 value 364.364435
## iter 70 value 361.518322
## iter 80 value 358.430676
## iter 90 value 354.106288
## iter 100 value 344.760108
## iter 110 value 329.244956
## iter 120 value 323.331036
## iter 130 value 314.874683
## iter 140 value 298.468662
## iter 150 value 293.466894
## iter 160 value 291.127964
## iter 170 value 286.607235
## iter 180 value 286.582480
## iter 190 value 284.383327
## iter 200 value 279.075062
## iter 210 value 273.146591
## iter 220 value 270.894268
## iter 230 value 268.879247
## iter 240 value 266.492753
## iter 250 value 263.919325
## iter 260 value 261.253079
## iter 270 value 256.938011
## iter 280 value 252.053964
## iter 290 value 248.975719
## iter 300 value 244.776661
## final value 244.776661
## stopped after 300 iterations
## # weights: 473
## initial value 628.085456
## iter 10 value 546.423891
## iter 20 value 418.840667
## iter 30 value 357.971620
## iter 40 value 353.192445
## iter 50 value 352.960941
## iter 60 value 352.804689
## iter 70 value 346.371344
## iter 80 value 341.215992
## iter 90 value 336.509283
## iter 100 value 330.302751
## iter 110 value 323.333410
## iter 120 value 320.970763
## iter 130 value 320.859505
## iter 140 value 320.858078
## iter 150 value 319.012876
## iter 160 value 318.997433
## iter 170 value 318.996734
## iter 180 value 317.471097
## iter 190 value 317.125075
## iter 200 value 317.124348
## final value 317.124030
## converged
## # weights: 473
## initial value 640.247384
## iter 10 value 554.368004
## iter 20 value 399.457649
## iter 30 value 327.719504
## iter 40 value 274.972919
## iter 50 value 232.909750
## iter 60 value 195.665148
## iter 70 value 176.715720
## iter 80 value 157.700957
## iter 90 value 142.401058
## iter 100 value 119.966969
## iter 110 value 110.766894
## iter 120 value 98.491016
## iter 130 value 78.108367
## iter 140 value 73.371239
## iter 150 value 70.750994
## iter 160 value 65.555626
## iter 170 value 59.705106
## iter 180 value 54.375063
## iter 190 value 53.221204
## iter 200 value 53.103880
## iter 210 value 53.086886
## iter 220 value 48.656967
## iter 230 value 48.345874
## iter 240 value 46.106633
## iter 250 value 43.434034
## iter 260 value 43.207654
## iter 270 value 43.180835
## iter 280 value 43.169798
## iter 290 value 43.165354
## iter 300 value 43.164194
## final value 43.164194
## stopped after 300 iterations
## # weights: 473
## initial value 628.523026
## iter 10 value 496.081979
## iter 20 value 422.675225
## iter 30 value 415.297281
## iter 40 value 411.295226
## iter 50 value 409.090203
## iter 60 value 406.021044
## iter 70 value 404.153426
## iter 80 value 402.601169
## iter 90 value 396.756143
## iter 100 value 393.483451
## iter 110 value 391.937269
## iter 120 value 390.049634
## iter 130 value 389.986427
## iter 140 value 386.909118
## iter 150 value 386.846378
## iter 160 value 382.447099
## iter 170 value 374.822750
## iter 180 value 370.893360
## iter 190 value 368.737596
## iter 200 value 367.360182
## iter 210 value 367.075425
## iter 220 value 363.842504
## iter 230 value 362.760513
## iter 240 value 354.145873
## iter 250 value 351.792207
## iter 260 value 351.177201
## iter 270 value 349.509667
## iter 280 value 348.006706
## iter 290 value 330.455008
## iter 300 value 328.082373
## final value 328.082373
## stopped after 300 iterations
## # weights: 473
## initial value 678.002685
## iter 10 value 597.360747
## iter 20 value 545.712629
## iter 30 value 538.272342
## iter 40 value 536.695069
## iter 50 value 535.606299
## iter 60 value 535.302676
## iter 70 value 531.909823
## iter 80 value 530.949808
## iter 90 value 530.945566
## iter 100 value 529.159424
## iter 110 value 529.142918
## iter 120 value 528.194544
## iter 130 value 526.333805
## iter 140 value 524.146985
## iter 150 value 520.854317
## iter 160 value 519.065781
## iter 170 value 515.862402
## iter 180 value 515.743298
## iter 190 value 515.740949
## iter 200 value 514.765835
## iter 210 value 513.782501
## iter 220 value 513.050682
## iter 230 value 510.100719
## iter 240 value 510.066169
## final value 510.066155
## converged
## # weights: 473
## initial value 662.642155
## iter 10 value 499.626166
## iter 20 value 392.575461
## iter 30 value 314.320772
## iter 40 value 271.629760
## iter 50 value 225.159460
## iter 60 value 201.924846
## iter 70 value 159.442484
## iter 80 value 145.250175
## iter 90 value 127.200436
## iter 100 value 106.227963
## iter 110 value 95.534061
## iter 120 value 85.610289
## iter 130 value 76.296315
## iter 140 value 72.030702
## iter 150 value 66.338114
## iter 160 value 62.402186
## iter 170 value 61.483710
## iter 180 value 55.129554
## iter 190 value 51.327608
## iter 200 value 48.138308
## iter 210 value 47.502385
## iter 220 value 43.098202
## iter 230 value 40.951450
## iter 240 value 37.538587
## iter 250 value 37.253153
## iter 260 value 37.240319
## iter 270 value 37.236079
## iter 280 value 37.234401
## iter 290 value 37.234231
## iter 300 value 37.234171
## final value 37.234171
## stopped after 300 iterations
## # weights: 473
## initial value 647.107112
## iter 10 value 550.207205
## iter 20 value 481.984269
## iter 30 value 413.373025
## iter 40 value 353.461767
## iter 50 value 300.065498
## iter 60 value 283.455856
## iter 70 value 274.269818
## iter 80 value 267.815783
## iter 90 value 263.983451
## iter 100 value 261.497542
## iter 110 value 260.900537
## iter 120 value 254.860490
## iter 130 value 251.819285
## iter 140 value 251.576745
## iter 150 value 251.559311
## iter 160 value 246.172614
## iter 170 value 245.961676
## iter 180 value 240.405343
## iter 190 value 234.749924
## iter 200 value 234.602715
## iter 210 value 234.594373
## iter 220 value 232.754538
## iter 230 value 232.305247
## iter 240 value 229.323275
## iter 250 value 223.408984
## iter 260 value 219.176258
## iter 270 value 212.228312
## iter 280 value 209.670301
## iter 290 value 203.698785
## iter 300 value 200.953696
## final value 200.953696
## stopped after 300 iterations
## # weights: 473
## initial value 645.607817
## iter 10 value 550.457675
## iter 20 value 362.936847
## iter 30 value 345.238268
## iter 40 value 341.367274
## iter 50 value 336.949603
## iter 60 value 332.015606
## iter 70 value 327.602998
## iter 80 value 326.377703
## iter 90 value 324.194848
## iter 100 value 316.931956
## iter 110 value 312.441560
## iter 120 value 310.408620
## iter 130 value 308.564765
## iter 140 value 304.549798
## iter 150 value 298.353540
## iter 160 value 295.710421
## iter 170 value 287.503151
## iter 180 value 280.076065
## iter 190 value 277.932871
## iter 200 value 273.705793
## iter 210 value 269.415769
## iter 220 value 269.010573
## iter 230 value 268.999987
## iter 240 value 263.420471
## iter 250 value 258.505653
## iter 260 value 255.759122
## iter 270 value 253.202138
## iter 280 value 253.198095
## iter 290 value 253.197102
## iter 300 value 250.883100
## final value 250.883100
## stopped after 300 iterations
## # weights: 473
## initial value 646.748018
## iter 10 value 624.077959
## iter 20 value 555.231468
## iter 30 value 520.212925
## iter 40 value 377.329259
## iter 50 value 293.111679
## iter 60 value 250.435138
## iter 70 value 224.142885
## iter 80 value 196.428583
## iter 90 value 173.266869
## iter 100 value 157.105836
## iter 110 value 147.680798
## iter 120 value 136.974880
## iter 130 value 130.981109
## iter 140 value 111.635512
## iter 150 value 98.262000
## iter 160 value 87.927666
## iter 170 value 79.181026
## iter 180 value 65.401008
## iter 190 value 60.202536
## iter 200 value 57.410696
## iter 210 value 55.578321
## iter 220 value 55.375307
## iter 230 value 55.336103
## iter 240 value 55.320815
## iter 250 value 55.314115
## iter 260 value 55.312546
## iter 270 value 55.312166
## iter 280 value 55.312118
## iter 290 value 55.312104
## iter 290 value 55.312104
## iter 290 value 55.312104
## final value 55.312104
## converged
## # weights: 473
## initial value 686.742129
## iter 10 value 627.997305
## iter 20 value 623.703484
## iter 30 value 586.263909
## iter 40 value 519.560661
## iter 50 value 484.925110
## iter 60 value 478.783484
## iter 70 value 475.498840
## iter 80 value 472.765286
## iter 90 value 462.370559
## iter 100 value 461.107607
## iter 110 value 458.781503
## iter 120 value 456.951882
## iter 130 value 453.835773
## iter 140 value 453.640923
## iter 150 value 453.124217
## iter 160 value 447.282268
## iter 170 value 444.599119
## iter 180 value 442.002338
## iter 190 value 436.484096
## iter 200 value 435.163985
## iter 210 value 431.150422
## iter 220 value 430.318325
## iter 230 value 428.152722
## iter 240 value 420.235981
## iter 250 value 396.694158
## iter 260 value 385.744144
## iter 270 value 383.827022
## iter 280 value 382.433157
## iter 290 value 380.172236
## iter 300 value 378.191497
## final value 378.191497
## stopped after 300 iterations
## # weights: 473
## initial value 641.511795
## iter 10 value 617.599545
## iter 20 value 549.876741
## iter 30 value 476.851718
## iter 40 value 466.540336
## iter 50 value 463.009351
## iter 60 value 455.793930
## iter 70 value 446.778603
## iter 80 value 444.441616
## iter 90 value 443.356487
## iter 100 value 439.860810
## iter 110 value 434.527198
## iter 120 value 434.473313
## iter 130 value 432.835815
## iter 140 value 431.924711
## iter 150 value 428.301354
## iter 160 value 421.131220
## iter 170 value 418.246611
## iter 180 value 415.033580
## iter 190 value 414.844138
## iter 200 value 412.490489
## iter 210 value 410.095257
## iter 220 value 407.629209
## iter 230 value 406.059787
## iter 240 value 403.502563
## iter 250 value 403.240146
## iter 260 value 403.236449
## iter 270 value 403.235719
## final value 403.235441
## converged
## # weights: 473
## initial value 737.946699
## iter 10 value 607.052234
## iter 20 value 539.827466
## iter 30 value 430.701528
## iter 40 value 351.377810
## iter 50 value 287.845432
## iter 60 value 246.044553
## iter 70 value 214.352914
## iter 80 value 190.847948
## iter 90 value 160.646164
## iter 100 value 139.680909
## iter 110 value 119.363596
## iter 120 value 109.944035
## iter 130 value 100.131130
## iter 140 value 90.304797
## iter 150 value 83.753118
## iter 160 value 77.220268
## iter 170 value 68.172506
## iter 180 value 59.588838
## iter 190 value 55.430638
## iter 200 value 49.701737
## iter 210 value 45.776758
## iter 220 value 41.829290
## iter 230 value 39.471288
## iter 240 value 38.569649
## iter 250 value 38.376023
## iter 260 value 38.294901
## iter 270 value 38.247759
## iter 280 value 38.236696
## iter 290 value 38.231382
## iter 300 value 38.230170
## final value 38.230170
## stopped after 300 iterations
## # weights: 473
## initial value 640.389176
## iter 10 value 605.463957
## iter 20 value 532.106315
## iter 30 value 445.771963
## iter 40 value 390.807370
## iter 50 value 342.967170
## iter 60 value 320.835260
## iter 70 value 301.062109
## iter 80 value 287.545283
## iter 90 value 279.597693
## iter 100 value 277.891822
## iter 110 value 274.944158
## iter 120 value 271.246371
## iter 130 value 271.064671
## iter 140 value 267.693159
## iter 150 value 267.228111
## iter 160 value 265.855987
## iter 170 value 262.026594
## iter 180 value 261.996271
## iter 190 value 261.980627
## iter 200 value 261.957542
## iter 210 value 258.600418
## iter 220 value 255.536445
## iter 230 value 252.740206
## iter 240 value 249.238272
## iter 250 value 249.219604
## iter 260 value 247.263831
## iter 270 value 247.228044
## iter 280 value 243.567561
## iter 290 value 243.218663
## iter 300 value 243.210280
## final value 243.210280
## stopped after 300 iterations
## # weights: 473
## initial value 652.333972
## iter 10 value 554.419666
## iter 20 value 405.768700
## iter 30 value 345.746477
## iter 40 value 308.969851
## iter 50 value 286.521962
## iter 60 value 269.539709
## iter 70 value 263.012231
## iter 80 value 261.028238
## iter 90 value 259.061467
## iter 100 value 257.169793
## iter 110 value 255.175361
## iter 120 value 253.272493
## iter 130 value 248.389760
## iter 140 value 241.153538
## iter 150 value 232.532114
## iter 160 value 227.173286
## iter 170 value 224.988522
## iter 180 value 220.719395
## iter 190 value 216.355384
## iter 200 value 214.333250
## iter 210 value 213.371833
## iter 220 value 209.767472
## iter 230 value 209.704505
## iter 240 value 207.511087
## iter 250 value 207.464136
## iter 260 value 207.461548
## iter 270 value 203.712527
## iter 280 value 203.695150
## iter 290 value 203.693903
## iter 300 value 203.692983
## final value 203.692983
## stopped after 300 iterations
## # weights: 473
## initial value 652.939541
## iter 10 value 508.957292
## iter 20 value 397.170428
## iter 30 value 315.130064
## iter 40 value 270.341747
## iter 50 value 223.426031
## iter 60 value 196.214394
## iter 70 value 168.244184
## iter 80 value 149.500841
## iter 90 value 122.155684
## iter 100 value 111.331325
## iter 110 value 98.638092
## iter 120 value 87.908341
## iter 130 value 84.344199
## iter 140 value 78.530389
## iter 150 value 69.307657
## iter 160 value 66.590659
## iter 170 value 61.788270
## iter 180 value 61.519519
## iter 190 value 57.158899
## iter 200 value 52.760075
## iter 210 value 52.103567
## iter 220 value 51.980622
## iter 230 value 51.963971
## iter 240 value 51.961590
## iter 250 value 51.961009
## iter 260 value 51.960869
## final value 51.960855
## converged
## # weights: 473
## initial value 629.430978
## iter 10 value 559.588677
## iter 20 value 396.739564
## iter 30 value 365.604900
## iter 40 value 336.914122
## iter 50 value 327.098373
## iter 60 value 323.168274
## iter 70 value 316.152794
## iter 80 value 310.680036
## iter 90 value 308.608937
## iter 100 value 306.432523
## iter 110 value 304.574809
## iter 120 value 304.289937
## iter 130 value 302.154540
## iter 140 value 301.791283
## iter 150 value 295.683883
## iter 160 value 293.489102
## iter 170 value 293.443177
## iter 180 value 293.391216
## iter 190 value 291.612292
## iter 200 value 291.183472
## iter 210 value 290.521321
## iter 220 value 288.918890
## iter 230 value 284.553914
## iter 240 value 282.192472
## iter 250 value 279.962442
## iter 260 value 277.620040
## iter 270 value 277.598996
## iter 280 value 273.083616
## iter 290 value 268.291634
## iter 300 value 258.809159
## final value 258.809159
## stopped after 300 iterations
## # weights: 473
## initial value 630.508606
## iter 10 value 532.014560
## iter 20 value 413.408554
## iter 30 value 372.833943
## iter 40 value 367.938192
## iter 50 value 364.497292
## iter 60 value 364.454421
## iter 70 value 362.692253
## iter 80 value 360.928132
## iter 90 value 359.170555
## iter 100 value 355.557858
## iter 110 value 355.540963
## iter 120 value 353.798520
## iter 130 value 353.719141
## iter 140 value 351.782196
## iter 150 value 349.897503
## iter 160 value 349.807264
## iter 170 value 346.128993
## iter 180 value 344.261689
## iter 190 value 342.369979
## iter 200 value 342.361659
## final value 342.361563
## converged
## # weights: 473
## initial value 675.543592
## iter 10 value 531.535065
## iter 20 value 413.123408
## iter 30 value 332.093238
## iter 40 value 301.497747
## iter 50 value 277.497319
## iter 60 value 245.754965
## iter 70 value 195.820038
## iter 80 value 178.738141
## iter 90 value 155.717520
## iter 100 value 133.813692
## iter 110 value 113.268735
## iter 120 value 103.137416
## iter 130 value 96.202388
## iter 140 value 89.598542
## iter 150 value 83.050714
## iter 160 value 76.350663
## iter 170 value 72.167435
## iter 180 value 65.750726
## iter 190 value 63.923494
## iter 200 value 57.119602
## iter 210 value 49.664612
## iter 220 value 47.931119
## iter 230 value 43.783050
## iter 240 value 42.363058
## iter 250 value 42.224488
## iter 260 value 42.211696
## iter 270 value 42.209121
## iter 280 value 42.208740
## iter 290 value 42.208624
## final value 42.208603
## converged
## # weights: 473
## initial value 631.694998
## iter 10 value 575.444151
## iter 20 value 503.928209
## iter 30 value 435.232438
## iter 40 value 359.446952
## iter 50 value 295.883284
## iter 60 value 217.191998
## iter 70 value 191.108789
## iter 80 value 164.254751
## iter 90 value 156.185633
## iter 100 value 149.975609
## iter 110 value 142.444507
## iter 120 value 135.735488
## iter 130 value 134.859256
## iter 140 value 134.718322
## iter 150 value 131.319297
## iter 160 value 126.203325
## iter 170 value 122.861846
## iter 180 value 122.584545
## iter 190 value 122.566403
## iter 200 value 122.558333
## iter 210 value 116.357191
## iter 220 value 116.221466
## iter 230 value 116.213801
## iter 240 value 116.210846
## iter 250 value 116.209064
## iter 260 value 109.993792
## iter 270 value 109.678080
## iter 280 value 109.646631
## iter 290 value 109.643727
## iter 300 value 109.642217
## final value 109.642217
## stopped after 300 iterations
## # weights: 473
## initial value 674.319059
## iter 10 value 627.052449
## iter 20 value 616.868858
## iter 30 value 587.651187
## iter 40 value 556.421901
## iter 50 value 516.370409
## iter 60 value 419.572840
## iter 70 value 395.112736
## iter 80 value 382.845946
## iter 90 value 379.421910
## iter 100 value 376.256725
## iter 110 value 372.853119
## iter 120 value 369.300808
## iter 130 value 364.227364
## iter 140 value 354.476120
## iter 150 value 348.229949
## iter 160 value 345.591196
## iter 170 value 342.989704
## iter 180 value 339.300958
## iter 190 value 337.817379
## iter 200 value 335.362897
## iter 210 value 334.851874
## iter 220 value 334.843986
## iter 230 value 331.963975
## iter 240 value 331.869753
## iter 250 value 327.750404
## iter 260 value 324.317474
## iter 270 value 324.308342
## iter 280 value 322.710181
## iter 290 value 319.693399
## iter 300 value 313.590495
## final value 313.590495
## stopped after 300 iterations
## # weights: 473
## initial value 648.358933
## iter 10 value 574.623647
## iter 20 value 498.606396
## iter 30 value 374.721258
## iter 40 value 296.109873
## iter 50 value 256.481515
## iter 60 value 220.592194
## iter 70 value 203.326108
## iter 80 value 182.014922
## iter 90 value 168.650983
## iter 100 value 151.134777
## iter 110 value 136.550709
## iter 120 value 128.951037
## iter 130 value 117.317400
## iter 140 value 104.121217
## iter 150 value 94.333802
## iter 160 value 85.808755
## iter 170 value 81.439486
## iter 180 value 77.812137
## iter 190 value 72.669843
## iter 200 value 66.650252
## iter 210 value 61.339762
## iter 220 value 58.051830
## iter 230 value 54.793306
## iter 240 value 50.316976
## iter 250 value 48.291150
## iter 260 value 47.800227
## iter 270 value 43.668494
## iter 280 value 43.037824
## iter 290 value 42.922760
## iter 300 value 42.911497
## final value 42.911497
## stopped after 300 iterations
## # weights: 473
## initial value 627.369671
## iter 10 value 470.911356
## iter 20 value 354.866182
## iter 30 value 325.079710
## iter 40 value 308.767335
## iter 50 value 306.052447
## iter 60 value 297.890177
## iter 70 value 297.440736
## iter 80 value 295.313154
## iter 90 value 293.036846
## iter 100 value 290.792662
## iter 110 value 288.278257
## iter 120 value 284.286398
## iter 130 value 282.291673
## iter 140 value 281.764963
## iter 150 value 279.576640
## iter 160 value 279.483536
## iter 170 value 277.330287
## iter 180 value 272.936411
## iter 190 value 270.558192
## iter 200 value 268.513355
## iter 210 value 268.135745
## iter 220 value 263.313812
## iter 230 value 258.572960
## iter 240 value 254.010188
## iter 250 value 251.406927
## iter 260 value 246.292786
## iter 270 value 241.864239
## iter 280 value 239.168025
## iter 290 value 233.969018
## iter 300 value 233.950648
## final value 233.950648
## stopped after 300 iterations
## # weights: 473
## initial value 641.311277
## iter 10 value 523.068053
## iter 20 value 375.798810
## iter 30 value 333.221173
## iter 40 value 302.064422
## iter 50 value 283.519523
## iter 60 value 274.695219
## iter 70 value 270.890678
## iter 80 value 265.239359
## iter 90 value 264.814823
## iter 100 value 261.330312
## iter 110 value 260.826298
## iter 120 value 259.316554
## iter 130 value 253.696839
## iter 140 value 251.800332
## iter 150 value 249.558621
## iter 160 value 247.506115
## iter 170 value 247.483879
## iter 180 value 247.480715
## iter 190 value 247.478277
## iter 200 value 239.834254
## iter 210 value 238.903538
## iter 220 value 238.898355
## iter 230 value 235.559794
## iter 240 value 233.472322
## iter 250 value 231.299753
## iter 260 value 231.296777
## iter 270 value 231.295768
## iter 280 value 229.544858
## iter 290 value 229.152633
## iter 300 value 225.784056
## final value 225.784056
## stopped after 300 iterations
## # weights: 473
## initial value 637.734888
## iter 10 value 492.681298
## iter 20 value 405.585268
## iter 30 value 338.985409
## iter 40 value 287.583211
## iter 50 value 244.954477
## iter 60 value 211.488662
## iter 70 value 185.001448
## iter 80 value 158.692032
## iter 90 value 142.437738
## iter 100 value 117.420584
## iter 110 value 108.555003
## iter 120 value 99.657249
## iter 130 value 90.906534
## iter 140 value 83.537046
## iter 150 value 76.116136
## iter 160 value 71.932787
## iter 170 value 69.948931
## iter 180 value 63.389963
## iter 190 value 57.735335
## iter 200 value 51.987234
## iter 210 value 51.667530
## iter 220 value 51.616954
## iter 230 value 51.566597
## iter 240 value 51.510107
## iter 250 value 51.494890
## iter 260 value 51.491825
## iter 270 value 51.490951
## iter 280 value 51.490772
## final value 51.490763
## converged
## # weights: 473
## initial value 649.430189
## iter 10 value 600.851003
## iter 20 value 563.712480
## iter 30 value 540.141219
## iter 40 value 512.667433
## iter 50 value 471.848632
## iter 60 value 429.950399
## iter 70 value 394.600804
## iter 80 value 379.084994
## iter 90 value 365.959679
## iter 100 value 347.177035
## iter 110 value 338.324024
## iter 120 value 335.198517
## iter 130 value 326.569029
## iter 140 value 321.746442
## iter 150 value 317.078111
## iter 160 value 315.013579
## iter 170 value 310.550142
## iter 180 value 303.927733
## iter 190 value 303.184985
## iter 200 value 302.025955
## iter 210 value 300.353442
## iter 220 value 300.296059
## iter 230 value 297.522674
## iter 240 value 291.136506
## iter 250 value 288.474412
## iter 260 value 286.620980
## iter 270 value 286.514577
## iter 280 value 277.458248
## iter 290 value 270.061588
## iter 300 value 266.899626
## final value 266.899626
## stopped after 300 iterations
## # weights: 473
## initial value 638.858241
## iter 10 value 589.614195
## iter 20 value 497.709945
## iter 30 value 409.630891
## iter 40 value 363.214142
## iter 50 value 345.961109
## iter 60 value 336.349806
## iter 70 value 325.476530
## iter 80 value 322.683175
## iter 90 value 320.784672
## iter 100 value 319.047181
## iter 110 value 314.721069
## iter 120 value 314.536941
## iter 130 value 312.812692
## iter 140 value 306.047256
## iter 150 value 294.962680
## iter 160 value 288.539339
## iter 170 value 285.672997
## iter 180 value 282.538837
## iter 190 value 280.611643
## iter 200 value 276.738754
## iter 210 value 273.395364
## iter 220 value 267.992323
## iter 230 value 265.858959
## iter 240 value 263.814083
## iter 250 value 260.854155
## iter 260 value 260.840657
## iter 270 value 257.935353
## iter 280 value 254.965725
## iter 290 value 253.682124
## iter 300 value 249.620022
## final value 249.620022
## stopped after 300 iterations
## # weights: 473
## initial value 645.929815
## iter 10 value 457.048483
## iter 20 value 337.263749
## iter 30 value 275.878396
## iter 40 value 238.937789
## iter 50 value 198.443003
## iter 60 value 180.978778
## iter 70 value 168.788752
## iter 80 value 147.070937
## iter 90 value 114.031936
## iter 100 value 98.807447
## iter 110 value 86.477659
## iter 120 value 80.331088
## iter 130 value 74.176379
## iter 140 value 64.611621
## iter 150 value 60.490874
## iter 160 value 53.552864
## iter 170 value 52.006313
## iter 180 value 51.607300
## iter 190 value 51.554022
## iter 200 value 51.537860
## iter 210 value 51.532320
## iter 220 value 51.531116
## iter 230 value 51.530755
## iter 240 value 51.530576
## final value 51.530550
## converged
## # weights: 473
## initial value 632.849926
## iter 10 value 593.117587
## iter 20 value 536.048876
## iter 30 value 465.463016
## iter 40 value 417.256519
## iter 50 value 372.927318
## iter 60 value 321.575489
## iter 70 value 287.245196
## iter 80 value 274.765739
## iter 90 value 268.805537
## iter 100 value 266.948022
## iter 110 value 265.102131
## iter 120 value 263.385211
## iter 130 value 263.194451
## iter 140 value 263.173726
## iter 150 value 263.131172
## iter 160 value 261.264494
## iter 170 value 261.243414
## iter 180 value 259.301667
## iter 190 value 257.473568
## iter 200 value 257.460742
## iter 210 value 255.551292
## iter 220 value 251.960440
## iter 230 value 251.422864
## iter 240 value 249.866882
## iter 250 value 247.947718
## iter 260 value 247.927635
## iter 270 value 245.947575
## iter 280 value 242.088571
## iter 290 value 238.390319
## iter 300 value 234.304050
## final value 234.304050
## stopped after 300 iterations
## # weights: 473
## initial value 627.821256
## iter 10 value 516.233612
## iter 20 value 354.061904
## iter 30 value 340.283649
## iter 40 value 327.750939
## iter 50 value 319.780824
## iter 60 value 309.851369
## iter 70 value 307.570275
## iter 80 value 307.496031
## iter 90 value 304.000688
## iter 100 value 297.040054
## iter 110 value 294.337741
## iter 120 value 289.580497
## iter 130 value 289.062516
## iter 140 value 289.057537
## iter 150 value 289.056537
## iter 160 value 289.056116
## iter 160 value 289.056114
## iter 160 value 289.056113
## final value 289.056113
## converged
## # weights: 473
## initial value 655.167730
## iter 10 value 478.720247
## iter 20 value 386.244549
## iter 30 value 315.093672
## iter 40 value 275.389556
## iter 50 value 208.248527
## iter 60 value 192.246899
## iter 70 value 176.516796
## iter 80 value 157.295623
## iter 90 value 142.362698
## iter 100 value 132.763906
## iter 110 value 123.899757
## iter 120 value 109.862194
## iter 130 value 98.086527
## iter 140 value 89.246269
## iter 150 value 79.471858
## iter 160 value 77.373297
## iter 170 value 71.326080
## iter 180 value 66.733172
## iter 190 value 66.134563
## iter 200 value 63.734283
## iter 210 value 58.995244
## iter 220 value 57.521228
## iter 230 value 53.834708
## iter 240 value 53.395335
## iter 250 value 53.338279
## iter 260 value 49.870265
## iter 270 value 47.813001
## iter 280 value 47.649566
## iter 290 value 47.633129
## iter 300 value 47.629035
## final value 47.629035
## stopped after 300 iterations
## # weights: 473
## initial value 630.025781
## iter 10 value 429.029849
## iter 20 value 322.774353
## iter 30 value 287.726360
## iter 40 value 255.325808
## iter 50 value 222.125476
## iter 60 value 208.715681
## iter 70 value 201.908904
## iter 80 value 197.884599
## iter 90 value 194.687677
## iter 100 value 191.369803
## iter 110 value 184.901745
## iter 120 value 184.829057
## iter 130 value 184.812680
## iter 140 value 184.796160
## iter 150 value 180.419879
## iter 160 value 178.410889
## iter 170 value 178.034599
## iter 180 value 178.024453
## iter 190 value 174.258729
## iter 200 value 173.296281
## iter 210 value 173.286563
## iter 220 value 173.280150
## iter 230 value 173.271822
## iter 240 value 170.895306
## iter 250 value 170.872275
## iter 260 value 170.868230
## iter 270 value 170.864037
## iter 280 value 166.029115
## iter 290 value 161.091796
## iter 300 value 161.073335
## final value 161.073335
## stopped after 300 iterations
## # weights: 473
## initial value 686.597664
## iter 10 value 615.759532
## iter 20 value 563.807103
## iter 30 value 469.577287
## iter 40 value 450.135891
## iter 50 value 426.772873
## iter 60 value 414.747551
## iter 70 value 395.810354
## iter 80 value 392.927373
## iter 90 value 386.647448
## iter 100 value 381.398089
## iter 110 value 379.169489
## iter 120 value 375.463742
## iter 130 value 373.341035
## iter 140 value 367.133536
## iter 150 value 361.601099
## iter 160 value 355.963894
## iter 170 value 348.852930
## iter 180 value 346.801578
## iter 190 value 344.688567
## iter 200 value 344.677943
## iter 210 value 342.718561
## iter 220 value 337.502191
## iter 230 value 336.706769
## iter 240 value 334.701934
## iter 250 value 332.762795
## iter 260 value 331.414712
## iter 270 value 330.805515
## iter 280 value 328.994463
## iter 290 value 328.842610
## iter 300 value 328.841170
## final value 328.841170
## stopped after 300 iterations
## # weights: 473
## initial value 725.393217
## iter 10 value 619.798103
## iter 20 value 519.261956
## iter 30 value 443.168810
## iter 40 value 386.000041
## iter 50 value 337.790911
## iter 60 value 314.444760
## iter 70 value 284.750130
## iter 80 value 269.149377
## iter 90 value 250.207851
## iter 100 value 236.478746
## iter 110 value 225.233612
## iter 120 value 201.236048
## iter 130 value 185.190020
## iter 140 value 170.114399
## iter 150 value 159.508413
## iter 160 value 151.929031
## iter 170 value 137.687287
## iter 180 value 131.485074
## iter 190 value 119.862870
## iter 200 value 112.301393
## iter 210 value 102.616763
## iter 220 value 94.820596
## iter 230 value 89.551847
## iter 240 value 79.333643
## iter 250 value 71.432446
## iter 260 value 68.446287
## iter 270 value 63.361234
## iter 280 value 60.957056
## iter 290 value 51.830191
## iter 300 value 49.689919
## final value 49.689919
## stopped after 300 iterations
## # weights: 473
## initial value 643.725588
## iter 10 value 516.219540
## iter 20 value 369.608755
## iter 30 value 308.006963
## iter 40 value 272.427650
## iter 50 value 249.990510
## iter 60 value 240.979300
## iter 70 value 235.422175
## iter 80 value 231.161682
## iter 90 value 231.112479
## iter 100 value 227.462556
## iter 110 value 221.652243
## iter 120 value 219.211600
## iter 130 value 217.202901
## iter 140 value 217.163771
## iter 150 value 215.109068
## iter 160 value 215.095534
## iter 170 value 213.031165
## iter 180 value 208.877414
## iter 190 value 208.861043
## iter 200 value 204.527851
## iter 210 value 200.244700
## iter 220 value 198.255438
## iter 230 value 196.093927
## iter 240 value 196.063736
## iter 250 value 193.173709
## iter 260 value 189.481690
## iter 270 value 189.448370
## iter 280 value 189.436687
## iter 290 value 187.228266
## iter 300 value 182.668391
## final value 182.668391
## stopped after 300 iterations
## # weights: 473
## initial value 709.002625
## iter 10 value 696.034469
## iter 20 value 665.463614
## iter 30 value 593.882236
## iter 40 value 515.897409
## iter 50 value 481.333926
## iter 60 value 463.021271
## iter 70 value 434.281347
## iter 80 value 417.572355
## iter 90 value 403.454472
## iter 100 value 390.038668
## iter 110 value 370.527799
## iter 120 value 351.451319
## iter 130 value 328.301312
## iter 140 value 287.938076
## iter 150 value 271.701007
## iter 160 value 253.551560
## iter 170 value 230.081813
## iter 180 value 215.015856
## iter 190 value 198.349865
## iter 200 value 188.094090
## iter 210 value 163.604171
## iter 220 value 124.990116
## iter 230 value 106.829785
## iter 240 value 95.995300
## iter 250 value 88.488007
## iter 260 value 77.361618
## iter 270 value 72.485787
## iter 280 value 68.926508
## iter 290 value 64.254913
## iter 300 value 54.139289
## final value 54.139289
## stopped after 300 iterationsmodel_nnet## Neural Network
##
## 1006 samples
## 470 predictor
## 2 classes: 'negative', 'positive'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 906, 905, 905, 905, 906, 905, ...
## Resampling results across tuning parameters:
##
## size decay Accuracy Kappa
## 1 0e+00 0.6988365 0.3974537
## 1 1e-04 0.7120248 0.4241541
## 1 1e-01 0.7452361 0.4905912
## 3 0e+00 NaN NaN
## 3 1e-04 NaN NaN
## 3 1e-01 NaN NaN
## 5 0e+00 NaN NaN
## 5 1e-04 NaN NaN
## 5 1e-01 NaN NaN
##
## Accuracy was used to select the optimal model using the largest value.
## The final values used for the model were size = 1 and decay = 0.1.plot(model_nnet)
13. Model-2: Training & tuning
As a second model, we choose XGBoost. Specifically, we choose a variant of it called xgbLinear because of the speed constraints.
More about boosting & xgboost: Boosting is an ensemble technique where new models are added to correct the errors made by existing models. Models are added sequentially until no further improvements can be made. A popular example is the AdaBoost algorithm that weights data points that are hard to predict.
Gradient boosting is an approach where new models are created that predict the residuals or errors of prior models and then added together to make the final prediction. It is called gradient boosting because it uses a gradient descent algorithm to minimize the loss when adding new models.
options(warn=-1)
ctrl <- trainControl(method = "repeatedcv",repeats=3)
model_xgb<-train(training[,predictors],training[,outcomeName],method='xgbLinear',
trControl=ctrl,tuneLength=3,
metric="Accuracy")model_xgb## eXtreme Gradient Boosting
##
## 1006 samples
## 470 predictor
## 2 classes: 'negative', 'positive'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 905, 906, 905, 905, 905, 906, ...
## Resampling results across tuning parameters:
##
## lambda alpha nrounds Accuracy Kappa
## 0e+00 0e+00 50 0.7381981 0.4762981
## 0e+00 0e+00 100 0.7431290 0.4861996
## 0e+00 0e+00 150 0.7480962 0.4961335
## 0e+00 1e-04 50 0.7375311 0.4750479
## 0e+00 1e-04 100 0.7454620 0.4908815
## 0e+00 1e-04 150 0.7464556 0.4928713
## 0e+00 1e-01 50 0.7286002 0.4572190
## 0e+00 1e-01 100 0.7371816 0.4743175
## 0e+00 1e-01 150 0.7381782 0.4763222
## 1e-04 0e+00 50 0.7375017 0.4749934
## 1e-04 0e+00 100 0.7434523 0.4868719
## 1e-04 0e+00 150 0.7480698 0.4961117
## 1e-04 1e-04 50 0.7371879 0.4743336
## 1e-04 1e-04 100 0.7471415 0.4942499
## 1e-04 1e-04 150 0.7448281 0.4895967
## 1e-04 1e-01 50 0.7288943 0.4578073
## 1e-04 1e-01 100 0.7355084 0.4709697
## 1e-04 1e-01 150 0.7418054 0.4835984
## 1e-01 0e+00 50 0.7378549 0.4757056
## 1e-01 0e+00 100 0.7484816 0.4969173
## 1e-01 0e+00 150 0.7537758 0.5075096
## 1e-01 1e-04 50 0.7335281 0.4670585
## 1e-01 1e-04 100 0.7517657 0.5035148
## 1e-01 1e-04 150 0.7524326 0.5048097
## 1e-01 1e-01 50 0.7315935 0.4631249
## 1e-01 1e-01 100 0.7421483 0.4842721
## 1e-01 1e-01 150 0.7424884 0.4849394
##
## Tuning parameter 'eta' was held constant at a value of 0.3
## Accuracy was used to select the optimal model using the largest value.
## The final values used for the model were nrounds = 150, lambda = 0.1, alpha =
## 0 and eta = 0.3.plot(model_xgb)
13.1 Plot feature importance of xgb model
importance = varImp(object=model_xgb)
plot(importance, top=20)
13.2 Plot feature importance of nnet model
importance = varImp(object=model_nnet)
plot(importance, top=20)
14. Feature selection
Source: https://topepo.github.io/caret/recursive-feature-elimination.html
# Number of features to consider. The model will consider given number of features & check the score against it.
subsets <- c(50, 75, 150, 200)The simulation will fit models with subset sizes of 50, 75, 150, 200
lrFuncs for logistic regression. rfFuncs for random Forest
We use fit linear models, the lrFuncs set of functions can be used. To do this, a control object is created with the rfeControl function. We also specify that repeated 10-fold cross-validation should be used in line 2.1 of Algorithm 2. The number of folds can be changed via the number argument to rfeControl (defaults to 10). The verbose option prevents copious amounts of output from being produced.
# Feature selection
ctrl <- rfeControl(functions = lrFuncs,
method = "repeatedcv",
repeats = 3,
verbose = FALSE)
lmProfile <- rfe(training[,predictors], training[,outcomeName],
sizes = subsets,
rfeControl = ctrl)See the results
lmProfile##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (10 fold, repeated 3 times)
##
## Resampling performance over subset size:
##
## Variables Accuracy Kappa AccuracySD KappaSD Selected
## 50 0.6882 0.3763 0.05029 0.10064
## 75 0.7100 0.4201 0.04201 0.08401 *
## 150 0.7042 0.4084 0.05292 0.10584
## 200 0.7032 0.4063 0.04701 0.09403
## 470 0.6845 0.3691 0.05299 0.10584
##
## The top 5 variables (out of 75):
## waste, great, didnt, deliver, performance150 features (words) seem to do the job really well. One can only use these 150 features if fast performance is needed. The following link can be referred for this,
15. Feature Extraction
For PCA, we can look at all the following links,
https://cmdlinetips.com/2019/04/introduction-to-pca-with-r-using-prcomp/
https://rstudio-pubs-static.s3.amazonaws.com/92006_344e916f251146daa0dc49fef94e2104.html
pca_res <- prcomp(training[,predictors])
summary(pca_res)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7
## Standard deviation 5.02965 3.82066 2.51668 2.14304 2.0519 1.96512 1.90512
## Proportion of Variance 0.09737 0.05618 0.02438 0.01768 0.0162 0.01486 0.01397
## Cumulative Proportion 0.09737 0.15355 0.17793 0.19560 0.2118 0.22667 0.24064
## PC8 PC9 PC10 PC11 PC12 PC13 PC14
## Standard deviation 1.79990 1.69958 1.66581 1.60280 1.58910 1.56867 1.53954
## Proportion of Variance 0.01247 0.01112 0.01068 0.00989 0.00972 0.00947 0.00912
## Cumulative Proportion 0.25311 0.26423 0.27491 0.28480 0.29452 0.30399 0.31311
## PC15 PC16 PC17 PC18 PC19 PC20 PC21
## Standard deviation 1.52842 1.51143 1.47007 1.4415 1.40883 1.40172 1.38550
## Proportion of Variance 0.00899 0.00879 0.00832 0.0080 0.00764 0.00756 0.00739
## Cumulative Proportion 0.32210 0.33089 0.33921 0.3472 0.35485 0.36241 0.36980
## PC22 PC23 PC24 PC25 PC26 PC27 PC28
## Standard deviation 1.37437 1.3484 1.34400 1.33009 1.3097 1.29040 1.2688
## Proportion of Variance 0.00727 0.0070 0.00695 0.00681 0.0066 0.00641 0.0062
## Cumulative Proportion 0.37707 0.3841 0.39102 0.39783 0.4044 0.41084 0.4170
## PC29 PC30 PC31 PC32 PC33 PC34 PC35
## Standard deviation 1.25700 1.24950 1.24423 1.23882 1.22586 1.21784 1.20107
## Proportion of Variance 0.00608 0.00601 0.00596 0.00591 0.00578 0.00571 0.00555
## Cumulative Proportion 0.42312 0.42912 0.43508 0.44099 0.44677 0.45248 0.45803
## PC36 PC37 PC38 PC39 PC40 PC41 PC42
## Standard deviation 1.19628 1.18633 1.1840 1.16162 1.13645 1.13256 1.12320
## Proportion of Variance 0.00551 0.00542 0.0054 0.00519 0.00497 0.00494 0.00486
## Cumulative Proportion 0.46354 0.46896 0.4744 0.47955 0.48452 0.48946 0.49431
## PC43 PC44 PC45 PC46 PC47 PC48 PC49
## Standard deviation 1.11781 1.10144 1.09776 1.09022 1.08836 1.07930 1.07600
## Proportion of Variance 0.00481 0.00467 0.00464 0.00457 0.00456 0.00448 0.00446
## Cumulative Proportion 0.49912 0.50379 0.50843 0.51300 0.51756 0.52205 0.52650
## PC50 PC51 PC52 PC53 PC54 PC55 PC56
## Standard deviation 1.06429 1.06094 1.05582 1.04693 1.03978 1.03376 1.02342
## Proportion of Variance 0.00436 0.00433 0.00429 0.00422 0.00416 0.00411 0.00403
## Cumulative Proportion 0.53086 0.53519 0.53949 0.54370 0.54786 0.55198 0.55601
## PC57 PC58 PC59 PC60 PC61 PC62 PC63
## Standard deviation 1.02130 1.01630 1.00949 1.0069 0.99873 0.99140 0.98290
## Proportion of Variance 0.00401 0.00398 0.00392 0.0039 0.00384 0.00378 0.00372
## Cumulative Proportion 0.56002 0.56400 0.56792 0.5718 0.57566 0.57945 0.58316
## PC64 PC65 PC66 PC67 PC68 PC69 PC70
## Standard deviation 0.97343 0.96643 0.96071 0.95115 0.94867 0.94473 0.94182
## Proportion of Variance 0.00365 0.00359 0.00355 0.00348 0.00346 0.00344 0.00341
## Cumulative Proportion 0.58681 0.59041 0.59396 0.59744 0.60090 0.60434 0.60775
## PC71 PC72 PC73 PC74 PC75 PC76 PC77
## Standard deviation 0.93631 0.93304 0.92733 0.92162 0.91548 0.90638 0.90472
## Proportion of Variance 0.00337 0.00335 0.00331 0.00327 0.00323 0.00316 0.00315
## Cumulative Proportion 0.61113 0.61448 0.61779 0.62106 0.62428 0.62745 0.63060
## PC78 PC79 PC80 PC81 PC82 PC83 PC84
## Standard deviation 0.89637 0.89345 0.88978 0.88757 0.88501 0.8832 0.87840
## Proportion of Variance 0.00309 0.00307 0.00305 0.00303 0.00301 0.0030 0.00297
## Cumulative Proportion 0.63369 0.63676 0.63981 0.64284 0.64585 0.6489 0.65183
## PC85 PC86 PC87 PC88 PC89 PC90 PC91
## Standard deviation 0.8675 0.86407 0.85998 0.85522 0.85451 0.84966 0.84499
## Proportion of Variance 0.0029 0.00287 0.00285 0.00282 0.00281 0.00278 0.00275
## Cumulative Proportion 0.6547 0.65760 0.66044 0.66326 0.66607 0.66885 0.67160
## PC92 PC93 PC94 PC95 PC96 PC97 PC98
## Standard deviation 0.84308 0.83897 0.83239 0.83122 0.82909 0.82705 0.8219
## Proportion of Variance 0.00274 0.00271 0.00267 0.00266 0.00265 0.00263 0.0026
## Cumulative Proportion 0.67433 0.67704 0.67971 0.68237 0.68501 0.68764 0.6902
## PC99 PC100 PC101 PC102 PC103 PC104 PC105
## Standard deviation 0.81535 0.80918 0.80730 0.8063 0.80372 0.80109 0.79552
## Proportion of Variance 0.00256 0.00252 0.00251 0.0025 0.00249 0.00247 0.00244
## Cumulative Proportion 0.69280 0.69532 0.69783 0.7003 0.70282 0.70529 0.70773
## PC106 PC107 PC108 PC109 PC110 PC111 PC112
## Standard deviation 0.79236 0.7896 0.78538 0.78337 0.77832 0.77521 0.77094
## Proportion of Variance 0.00242 0.0024 0.00237 0.00236 0.00233 0.00231 0.00229
## Cumulative Proportion 0.71014 0.7125 0.71492 0.71728 0.71961 0.72192 0.72421
## PC113 PC114 PC115 PC116 PC117 PC118 PC119
## Standard deviation 0.76827 0.76399 0.75915 0.75817 0.7552 0.75372 0.74938
## Proportion of Variance 0.00227 0.00225 0.00222 0.00221 0.0022 0.00219 0.00216
## Cumulative Proportion 0.72648 0.72873 0.73095 0.73316 0.7353 0.73754 0.73970
## PC120 PC121 PC122 PC123 PC124 PC125 PC126
## Standard deviation 0.74577 0.74499 0.74309 0.7378 0.73427 0.73245 0.72534
## Proportion of Variance 0.00214 0.00214 0.00213 0.0021 0.00208 0.00206 0.00202
## Cumulative Proportion 0.74184 0.74398 0.74610 0.7482 0.75028 0.75234 0.75437
## PC127 PC128 PC129 PC130 PC131 PC132 PC133
## Standard deviation 0.72286 0.7216 0.7203 0.71652 0.71538 0.71166 0.70768
## Proportion of Variance 0.00201 0.0020 0.0020 0.00198 0.00197 0.00195 0.00193
## Cumulative Proportion 0.75638 0.7584 0.7604 0.76235 0.76432 0.76627 0.76820
## PC134 PC135 PC136 PC137 PC138 PC139 PC140
## Standard deviation 0.70417 0.69879 0.69698 0.69388 0.68780 0.68755 0.6840
## Proportion of Variance 0.00191 0.00188 0.00187 0.00185 0.00182 0.00182 0.0018
## Cumulative Proportion 0.77011 0.77199 0.77386 0.77571 0.77753 0.77935 0.7812
## PC141 PC142 PC143 PC144 PC145 PC146 PC147
## Standard deviation 0.68262 0.68019 0.67886 0.67490 0.67304 0.67220 0.66618
## Proportion of Variance 0.00179 0.00178 0.00177 0.00175 0.00174 0.00174 0.00171
## Cumulative Proportion 0.78295 0.78473 0.78650 0.78825 0.79000 0.79174 0.79344
## PC148 PC149 PC150 PC151 PC152 PC153 PC154
## Standard deviation 0.6654 0.66320 0.66058 0.65671 0.65197 0.65059 0.64884
## Proportion of Variance 0.0017 0.00169 0.00168 0.00166 0.00164 0.00163 0.00162
## Cumulative Proportion 0.7952 0.79684 0.79852 0.80018 0.80182 0.80345 0.80507
## PC155 PC156 PC157 PC158 PC159 PC160 PC161
## Standard deviation 0.64767 0.6443 0.64063 0.64019 0.63873 0.63663 0.63516
## Proportion of Variance 0.00161 0.0016 0.00158 0.00158 0.00157 0.00156 0.00155
## Cumulative Proportion 0.80668 0.8083 0.80986 0.81143 0.81301 0.81457 0.81612
## PC162 PC163 PC164 PC165 PC166 PC167 PC168
## Standard deviation 0.63184 0.62895 0.62729 0.62088 0.61885 0.61750 0.61342
## Proportion of Variance 0.00154 0.00152 0.00151 0.00148 0.00147 0.00147 0.00145
## Cumulative Proportion 0.81765 0.81918 0.82069 0.82218 0.82365 0.82512 0.82657
## PC169 PC170 PC171 PC172 PC173 PC174 PC175
## Standard deviation 0.61243 0.60983 0.60798 0.60647 0.60553 0.60143 0.59996
## Proportion of Variance 0.00144 0.00143 0.00142 0.00142 0.00141 0.00139 0.00139
## Cumulative Proportion 0.82801 0.82944 0.83086 0.83228 0.83369 0.83508 0.83647
## PC176 PC177 PC178 PC179 PC180 PC181 PC182
## Standard deviation 0.59922 0.59572 0.59466 0.59354 0.59191 0.58859 0.58681
## Proportion of Variance 0.00138 0.00137 0.00136 0.00136 0.00135 0.00133 0.00133
## Cumulative Proportion 0.83785 0.83922 0.84058 0.84193 0.84328 0.84461 0.84594
## PC183 PC184 PC185 PC186 PC187 PC188 PC189
## Standard deviation 0.58523 0.58379 0.5818 0.57752 0.57574 0.57494 0.57283
## Proportion of Variance 0.00132 0.00131 0.0013 0.00128 0.00128 0.00127 0.00126
## Cumulative Proportion 0.84726 0.84857 0.8499 0.85116 0.85243 0.85370 0.85497
## PC190 PC191 PC192 PC193 PC194 PC195 PC196
## Standard deviation 0.56865 0.56679 0.56657 0.56581 0.56327 0.55964 0.5579
## Proportion of Variance 0.00124 0.00124 0.00124 0.00123 0.00122 0.00121 0.0012
## Cumulative Proportion 0.85621 0.85745 0.85868 0.85992 0.86114 0.86234 0.8635
## PC197 PC198 PC199 PC200 PC201 PC202 PC203
## Standard deviation 0.55588 0.55302 0.55093 0.54862 0.54588 0.54519 0.54497
## Proportion of Variance 0.00119 0.00118 0.00117 0.00116 0.00115 0.00114 0.00114
## Cumulative Proportion 0.86473 0.86591 0.86707 0.86823 0.86938 0.87052 0.87167
## PC204 PC205 PC206 PC207 PC208 PC209 PC210
## Standard deviation 0.54175 0.54023 0.53707 0.53625 0.5355 0.53279 0.53050
## Proportion of Variance 0.00113 0.00112 0.00111 0.00111 0.0011 0.00109 0.00108
## Cumulative Proportion 0.87280 0.87392 0.87503 0.87614 0.8772 0.87833 0.87942
## PC211 PC212 PC213 PC214 PC215 PC216 PC217
## Standard deviation 0.52902 0.52796 0.52700 0.52394 0.52317 0.52050 0.51821
## Proportion of Variance 0.00108 0.00107 0.00107 0.00106 0.00105 0.00104 0.00103
## Cumulative Proportion 0.88049 0.88157 0.88264 0.88369 0.88475 0.88579 0.88682
## PC218 PC219 PC220 PC221 PC222 PC223 PC224
## Standard deviation 0.51790 0.51571 0.51238 0.5108 0.50815 0.50727 0.50404
## Proportion of Variance 0.00103 0.00102 0.00101 0.0010 0.00099 0.00099 0.00098
## Cumulative Proportion 0.88785 0.88888 0.88989 0.8909 0.89189 0.89288 0.89385
## PC225 PC226 PC227 PC228 PC229 PC230 PC231
## Standard deviation 0.50300 0.50042 0.49839 0.49690 0.49525 0.49357 0.49104
## Proportion of Variance 0.00097 0.00096 0.00096 0.00095 0.00094 0.00094 0.00093
## Cumulative Proportion 0.89483 0.89579 0.89675 0.89770 0.89864 0.89958 0.90051
## PC232 PC233 PC234 PC235 PC236 PC237 PC238
## Standard deviation 0.48989 0.48957 0.48736 0.48491 0.4842 0.48102 0.48043
## Proportion of Variance 0.00092 0.00092 0.00091 0.00091 0.0009 0.00089 0.00089
## Cumulative Proportion 0.90143 0.90235 0.90327 0.90417 0.9051 0.90597 0.90686
## PC239 PC240 PC241 PC242 PC243 PC244 PC245
## Standard deviation 0.47961 0.47778 0.47467 0.47325 0.47187 0.46934 0.46750
## Proportion of Variance 0.00089 0.00088 0.00087 0.00086 0.00086 0.00085 0.00084
## Cumulative Proportion 0.90774 0.90862 0.90949 0.91035 0.91121 0.91205 0.91289
## PC246 PC247 PC248 PC249 PC250 PC251 PC252
## Standard deviation 0.46600 0.46352 0.46208 0.46074 0.45998 0.4568 0.4553
## Proportion of Variance 0.00084 0.00083 0.00082 0.00082 0.00081 0.0008 0.0008
## Cumulative Proportion 0.91373 0.91456 0.91538 0.91620 0.91701 0.9178 0.9186
## PC253 PC254 PC255 PC256 PC257 PC258 PC259
## Standard deviation 0.45347 0.45244 0.45066 0.44983 0.44756 0.44641 0.44333
## Proportion of Variance 0.00079 0.00079 0.00078 0.00078 0.00077 0.00077 0.00076
## Cumulative Proportion 0.91940 0.92019 0.92097 0.92175 0.92252 0.92329 0.92405
## PC260 PC261 PC262 PC263 PC264 PC265 PC266
## Standard deviation 0.44306 0.44189 0.43937 0.43788 0.43626 0.43429 0.43343
## Proportion of Variance 0.00076 0.00075 0.00074 0.00074 0.00073 0.00073 0.00072
## Cumulative Proportion 0.92480 0.92555 0.92630 0.92703 0.92777 0.92849 0.92922
## PC267 PC268 PC269 PC270 PC271 PC272 PC273
## Standard deviation 0.43240 0.43056 0.42905 0.4261 0.4255 0.42416 0.42194
## Proportion of Variance 0.00072 0.00071 0.00071 0.0007 0.0007 0.00069 0.00069
## Cumulative Proportion 0.92994 0.93065 0.93136 0.9321 0.9327 0.93345 0.93413
## PC274 PC275 PC276 PC277 PC278 PC279 PC280
## Standard deviation 0.42144 0.41833 0.41699 0.41525 0.41315 0.41097 0.41009
## Proportion of Variance 0.00068 0.00067 0.00067 0.00066 0.00066 0.00065 0.00065
## Cumulative Proportion 0.93481 0.93549 0.93616 0.93682 0.93748 0.93813 0.93878
## PC281 PC282 PC283 PC284 PC285 PC286 PC287
## Standard deviation 0.40792 0.40664 0.40578 0.40522 0.40304 0.40168 0.40122
## Proportion of Variance 0.00064 0.00064 0.00063 0.00063 0.00063 0.00062 0.00062
## Cumulative Proportion 0.93942 0.94005 0.94069 0.94132 0.94194 0.94256 0.94318
## PC288 PC289 PC290 PC291 PC292 PC293 PC294
## Standard deviation 0.40011 0.39798 0.39737 0.3951 0.3941 0.3932 0.39124
## Proportion of Variance 0.00062 0.00061 0.00061 0.0006 0.0006 0.0006 0.00059
## Cumulative Proportion 0.94380 0.94441 0.94502 0.9456 0.9462 0.9468 0.94740
## PC295 PC296 PC297 PC298 PC299 PC300 PC301
## Standard deviation 0.38959 0.38709 0.38628 0.38508 0.38381 0.38170 0.38121
## Proportion of Variance 0.00058 0.00058 0.00057 0.00057 0.00057 0.00056 0.00056
## Cumulative Proportion 0.94798 0.94856 0.94914 0.94971 0.95027 0.95083 0.95139
## PC302 PC303 PC304 PC305 PC306 PC307 PC308
## Standard deviation 0.37964 0.37851 0.37686 0.37501 0.37394 0.37304 0.37224
## Proportion of Variance 0.00055 0.00055 0.00055 0.00054 0.00054 0.00054 0.00053
## Cumulative Proportion 0.95195 0.95250 0.95305 0.95359 0.95413 0.95466 0.95519
## PC309 PC310 PC311 PC312 PC313 PC314 PC315
## Standard deviation 0.37034 0.36762 0.36670 0.36473 0.36438 0.3617 0.3605
## Proportion of Variance 0.00053 0.00052 0.00052 0.00051 0.00051 0.0005 0.0005
## Cumulative Proportion 0.95572 0.95624 0.95676 0.95727 0.95778 0.9583 0.9588
## PC316 PC317 PC318 PC319 PC320 PC321 PC322
## Standard deviation 0.3597 0.3595 0.35818 0.35528 0.35466 0.35329 0.35095
## Proportion of Variance 0.0005 0.0005 0.00049 0.00049 0.00048 0.00048 0.00047
## Cumulative Proportion 0.9593 0.9598 0.96028 0.96076 0.96125 0.96173 0.96220
## PC323 PC324 PC325 PC326 PC327 PC328 PC329
## Standard deviation 0.35037 0.34926 0.34753 0.34700 0.34515 0.34395 0.34231
## Proportion of Variance 0.00047 0.00047 0.00046 0.00046 0.00046 0.00046 0.00045
## Cumulative Proportion 0.96267 0.96314 0.96361 0.96407 0.96453 0.96498 0.96544
## PC330 PC331 PC332 PC333 PC334 PC335 PC336
## Standard deviation 0.34131 0.33776 0.33615 0.33547 0.33490 0.33382 0.33143
## Proportion of Variance 0.00045 0.00044 0.00043 0.00043 0.00043 0.00043 0.00042
## Cumulative Proportion 0.96588 0.96632 0.96676 0.96719 0.96762 0.96805 0.96847
## PC337 PC338 PC339 PC340 PC341 PC342 PC343
## Standard deviation 0.33033 0.32975 0.32819 0.32693 0.32493 0.32481 0.3231
## Proportion of Variance 0.00042 0.00042 0.00041 0.00041 0.00041 0.00041 0.0004
## Cumulative Proportion 0.96889 0.96931 0.96973 0.97014 0.97055 0.97095 0.9714
## PC344 PC345 PC346 PC347 PC348 PC349 PC350
## Standard deviation 0.3226 0.3204 0.31957 0.31914 0.31657 0.31429 0.31357
## Proportion of Variance 0.0004 0.0004 0.00039 0.00039 0.00039 0.00038 0.00038
## Cumulative Proportion 0.9718 0.9721 0.97254 0.97293 0.97332 0.97370 0.97408
## PC351 PC352 PC353 PC354 PC355 PC356 PC357
## Standard deviation 0.31108 0.31039 0.30964 0.30786 0.30663 0.30422 0.30347
## Proportion of Variance 0.00037 0.00037 0.00037 0.00036 0.00036 0.00036 0.00035
## Cumulative Proportion 0.97445 0.97482 0.97519 0.97556 0.97592 0.97627 0.97663
## PC358 PC359 PC360 PC361 PC362 PC363 PC364
## Standard deviation 0.30230 0.30144 0.30034 0.29952 0.29809 0.29605 0.29426
## Proportion of Variance 0.00035 0.00035 0.00035 0.00035 0.00034 0.00034 0.00033
## Cumulative Proportion 0.97698 0.97733 0.97768 0.97802 0.97836 0.97870 0.97903
## PC365 PC366 PC367 PC368 PC369 PC370 PC371
## Standard deviation 0.29312 0.29218 0.29039 0.28824 0.28723 0.28592 0.28526
## Proportion of Variance 0.00033 0.00033 0.00032 0.00032 0.00032 0.00031 0.00031
## Cumulative Proportion 0.97937 0.97969 0.98002 0.98034 0.98066 0.98097 0.98128
## PC372 PC373 PC374 PC375 PC376 PC377 PC378
## Standard deviation 0.28442 0.28295 0.28228 0.2780 0.27670 0.27607 0.27500
## Proportion of Variance 0.00031 0.00031 0.00031 0.0003 0.00029 0.00029 0.00029
## Cumulative Proportion 0.98159 0.98190 0.98221 0.9825 0.98280 0.98310 0.98339
## PC379 PC380 PC381 PC382 PC383 PC384 PC385
## Standard deviation 0.27295 0.27121 0.27065 0.26897 0.26824 0.26688 0.26586
## Proportion of Variance 0.00029 0.00028 0.00028 0.00028 0.00028 0.00027 0.00027
## Cumulative Proportion 0.98367 0.98396 0.98424 0.98452 0.98479 0.98507 0.98534
## PC386 PC387 PC388 PC389 PC390 PC391 PC392
## Standard deviation 0.26425 0.26378 0.26294 0.26131 0.26039 0.25909 0.25894
## Proportion of Variance 0.00027 0.00027 0.00027 0.00026 0.00026 0.00026 0.00026
## Cumulative Proportion 0.98561 0.98588 0.98614 0.98640 0.98667 0.98692 0.98718
## PC393 PC394 PC395 PC396 PC397 PC398 PC399
## Standard deviation 0.25775 0.25468 0.25408 0.25333 0.25295 0.25091 0.24939
## Proportion of Variance 0.00026 0.00025 0.00025 0.00025 0.00025 0.00024 0.00024
## Cumulative Proportion 0.98744 0.98769 0.98794 0.98818 0.98843 0.98867 0.98891
## PC400 PC401 PC402 PC403 PC404 PC405 PC406
## Standard deviation 0.24853 0.24594 0.24519 0.24463 0.24128 0.24086 0.23868
## Proportion of Variance 0.00024 0.00023 0.00023 0.00023 0.00022 0.00022 0.00022
## Cumulative Proportion 0.98915 0.98938 0.98961 0.98984 0.99007 0.99029 0.99051
## PC407 PC408 PC409 PC410 PC411 PC412 PC413
## Standard deviation 0.23861 0.23741 0.23540 0.23405 0.23285 0.23085 0.2298
## Proportion of Variance 0.00022 0.00022 0.00021 0.00021 0.00021 0.00021 0.0002
## Cumulative Proportion 0.99073 0.99095 0.99116 0.99137 0.99158 0.99178 0.9920
## PC414 PC415 PC416 PC417 PC418 PC419 PC420
## Standard deviation 0.2289 0.2271 0.2261 0.22442 0.22382 0.22303 0.22163
## Proportion of Variance 0.0002 0.0002 0.0002 0.00019 0.00019 0.00019 0.00019
## Cumulative Proportion 0.9922 0.9924 0.9926 0.99278 0.99297 0.99316 0.99335
## PC421 PC422 PC423 PC424 PC425 PC426 PC427
## Standard deviation 0.21948 0.21857 0.21770 0.21574 0.21489 0.21216 0.21193
## Proportion of Variance 0.00019 0.00018 0.00018 0.00018 0.00018 0.00017 0.00017
## Cumulative Proportion 0.99354 0.99372 0.99390 0.99408 0.99426 0.99443 0.99461
## PC428 PC429 PC430 PC431 PC432 PC433 PC434
## Standard deviation 0.21054 0.20847 0.20738 0.20558 0.20382 0.20361 0.20177
## Proportion of Variance 0.00017 0.00017 0.00017 0.00016 0.00016 0.00016 0.00016
## Cumulative Proportion 0.99478 0.99494 0.99511 0.99527 0.99543 0.99559 0.99575
## PC435 PC436 PC437 PC438 PC439 PC440 PC441
## Standard deviation 0.20028 0.19965 0.19768 0.19673 0.19600 0.19499 0.19344
## Proportion of Variance 0.00015 0.00015 0.00015 0.00015 0.00015 0.00015 0.00014
## Cumulative Proportion 0.99590 0.99606 0.99621 0.99636 0.99650 0.99665 0.99679
## PC442 PC443 PC444 PC445 PC446 PC447 PC448
## Standard deviation 0.19223 0.19033 0.18860 0.18758 0.18507 0.18428 0.18266
## Proportion of Variance 0.00014 0.00014 0.00014 0.00014 0.00013 0.00013 0.00013
## Cumulative Proportion 0.99694 0.99708 0.99721 0.99735 0.99748 0.99761 0.99774
## PC449 PC450 PC451 PC452 PC453 PC454 PC455
## Standard deviation 0.18050 0.17911 0.17872 0.17688 0.17465 0.17401 0.17237
## Proportion of Variance 0.00013 0.00012 0.00012 0.00012 0.00012 0.00012 0.00011
## Cumulative Proportion 0.99786 0.99799 0.99811 0.99823 0.99835 0.99846 0.99858
## PC456 PC457 PC458 PC459 PC460 PC461 PC462
## Standard deviation 0.16868 0.16775 0.16573 0.1651 0.1640 0.1606 0.1598
## Proportion of Variance 0.00011 0.00011 0.00011 0.0001 0.0001 0.0001 0.0001
## Cumulative Proportion 0.99869 0.99880 0.99890 0.9990 0.9991 0.9992 0.9993
## PC463 PC464 PC465 PC466 PC467 PC468 PC469
## Standard deviation 0.1577 0.15672 0.15376 0.15030 0.14935 0.14786 0.14569
## Proportion of Variance 0.0001 0.00009 0.00009 0.00009 0.00009 0.00008 0.00008
## Cumulative Proportion 0.9994 0.99950 0.99959 0.99968 0.99976 0.99985 0.99993
## PC470
## Standard deviation 0.13603
## Proportion of Variance 0.00007
## Cumulative Proportion 1.00000fviz_eig(pca_res, )
Maximum variance explained by the principal component is 10%, which is quite low. This doesn’t mean being PCA good or bad. The values we have, where two principal components do not explain a big part of variance, mean that the data is far from being near a 2 dimensional subspace. It can be inferred that the current data has many dimensions, as the variance of the second component only explains 5% and rest of components must explain even less.
Find more on why this happens here -> https://stats.stackexchange.com/a/464203
typeColor <- ((training$classlabeltype=="negative")*1 + 1)
prComp <- prcomp(log10(training[,predictors]+1))
plot(prComp$x[,1],prComp$x[,2],col=typeColor,xlab="PC1",ylab="PC2")
By plotting the two principal dimensions, we could notice that there is no clear demarcation between negative and positive classes across the principal dimensions 1,2.
16. Predictions
16.1 Predictions using XGB model and confusion matrix calculation
predictions<-predict.train(object=model_xgb,testing[,predictors],type="raw")
confusionMatrix(predictions,testing[,outcomeName]) ## Confusion Matrix and Statistics
##
## Reference
## Prediction negative positive
## negative 128 46
## positive 39 121
##
## Accuracy : 0.7455
## 95% CI : (0.6952, 0.7914)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.491
##
## Mcnemar's Test P-Value : 0.5152
##
## Sensitivity : 0.7665
## Specificity : 0.7246
## Pos Pred Value : 0.7356
## Neg Pred Value : 0.7563
## Prevalence : 0.5000
## Detection Rate : 0.3832
## Detection Prevalence : 0.5210
## Balanced Accuracy : 0.7455
##
## 'Positive' Class : negative
## 16.2 Apart from the above shown way, one can also predict in a different way
x = subset(testing, select = -classlabeltype)
xgbModelClasses <- predict(model_xgb, newdata = x)
confusionMatrix(data=xgbModelClasses,testing$classlabeltype)## Confusion Matrix and Statistics
##
## Reference
## Prediction negative positive
## negative 128 46
## positive 39 121
##
## Accuracy : 0.7455
## 95% CI : (0.6952, 0.7914)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.491
##
## Mcnemar's Test P-Value : 0.5152
##
## Sensitivity : 0.7665
## Specificity : 0.7246
## Pos Pred Value : 0.7356
## Neg Pred Value : 0.7563
## Prevalence : 0.5000
## Detection Rate : 0.3832
## Detection Prevalence : 0.5210
## Balanced Accuracy : 0.7455
##
## 'Positive' Class : negative
## 16.3 Predictions using NNET model and confusion matrix calculation
predictions<-predict.train(object=model_nnet,testing[,predictors],type="raw")
confusionMatrix(predictions,testing[,outcomeName]) ## Confusion Matrix and Statistics
##
## Reference
## Prediction negative positive
## negative 121 45
## positive 46 122
##
## Accuracy : 0.7275
## 95% CI : (0.6764, 0.7746)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.4551
##
## Mcnemar's Test P-Value : 1
##
## Sensitivity : 0.7246
## Specificity : 0.7305
## Pos Pred Value : 0.7289
## Neg Pred Value : 0.7262
## Prevalence : 0.5000
## Detection Rate : 0.3623
## Detection Prevalence : 0.4970
## Balanced Accuracy : 0.7275
##
## 'Positive' Class : negative
## 17 Statistical comparison between your pair of selected classifiers
Now, we check which of the two classifiers is the best. For that, we get all the re-samples -> 30 from 3 (repeats of) x 10 (10-fold cross-validation process). For each of these 30 samples, we check the performance of the classifiers.
resamps=resamples(list(xgbTree=model_xgb,nnet=model_nnet),)
summary(resamps)##
## Call:
## summary.resamples(object = resamps)
##
## Models: xgbTree, nnet
## Number of resamples: 30
##
## Accuracy
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## xgbTree 0.6831683 0.7326733 0.7562376 0.7537758 0.7791337 0.83 0
## nnet 0.6700000 0.7206931 0.7376471 0.7452361 0.7780693 0.82 0
##
## Kappa
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## xgbTree 0.3655281 0.4648215 0.5124995 0.5075096 0.5579788 0.66 0
## nnet 0.3400000 0.4414269 0.4752941 0.4905912 0.5561051 0.64 0xyplot(resamps,what="BlandAltman")
The resulting plot has a lot of details to infer. Each dot refers to a resample. So, there are 30 dots (30 resamples).
Average accuracy is around 74 & max accuracy is around 80. Out of these 30 resamples, xgb performs better on 16 resamples (look at the y-column xgb - nnet. Positive values mean xgb has better score than nnet) and nnet on the remaining 14 resamples. This suggests that models are comparatively similar in performance. But to know if they’re actually similar, we need to perform a t-test to get the p-value. We use diff function to calculate the p-value which will be used in analyzing the significance of the differences between compared classifiers. In its current implementation, caret applies a t-test to obtain the significance of the differences between the pair of compared classifiers.
We pass the resampled object results into diff for p-value calculation. We use summary
diffs<-diff(resamps)
summary(diffs)##
## Call:
## summary.diff.resamples(object = diffs)
##
## p-value adjustment: bonferroni
## Upper diagonal: estimates of the difference
## Lower diagonal: p-value for H0: difference = 0
##
## Accuracy
## xgbTree nnet
## xgbTree 0.00854
## nnet 0.3959
##
## Kappa
## xgbTree nnet
## xgbTree 0.01692
## nnet 0.4008We can also use Dotplot. It is also used to look at the mean of difference of two models’ scores
# dot plots of results
dotplot(diffs)
We can also use compare_models to verify the observations obtained from diff. Source: https://cran.r-project.org/web/packages/caret/caret.pdf
compare_models(model_xgb, model_nnet)##
## One Sample t-test
##
## data: x
## t = 0.86182, df = 29, p-value = 0.3959
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.01172615 0.02880542
## sample estimates:
## mean of x
## 0.008539636As per compare_models & diff function, Since the p-value is high (0.39) > 0.05, we can say that we have no evidence against the Null hypothesis (that they’re similar). If the p-value is larger than 0.05, we cannot conclude that a significant difference exists.