
Let Agents do the talking: A Scalable Way to Evaluate Multi-Turn Chatbots
This piece grew out of a conversation with Niklas Finken.
About
In this post, let’s talk about “interactive evaluations” — a lightweight, automated way to test multi-turn chatbots at scale.
Large language models evolve quickly. A tweak to the system prompt, a new retrieval source, or a model upgrade can silently break conversation flow in ways that one-shot benchmarks never reveal. Interactive evaluations treat your bot like a real chat partner: a User-Agent drives the dialogue with natural follow-up questions, while a Critic-Agent reviews the entire transcript for factuality, helpfulness, and tone.
Background
Imagine you’ve just launched your chatbot, and initial user feedback is fantastic. Soon after, you’re told to add a few tweaks: tightening responses for brevity, adding guardrails to prevent off-topic conversations, or even adjusting the system prompts for better clarity. You confidently make these changes, expecting an even better user experience.
However, a few days later, you notice something troubling - the chat assistant isn’t vibing with users as before. Conversations feel stiff, incomplete, or oddly truncated. Your PM is puzzled, engineers are scratching their heads, and management is beginning to question what went wrong. Without systematic evaluations, identifying the exact cause becomes guesswork at best, potentially leading to further ineffective changes.

Figure 1: A tongue-in-cheek "this-is-fine" scene that captures how hidden regressions can burn in the background when changes ship without proper evaluations.
Why Evaluations are Essential?
Evaluations systematically track how each incremental change impacts performance, highlighting any unintended consequences. Rather than relying solely on intuition or anecdotal feedback, evals provide actionable insights and clear accountability, making it easier for teams to make informed decisions confidently.
As someone who often threatened or bribed LLMs to get work done, it was quite difficult to know which warnings/rewards got hold of the LLM without evals.
More time I spent in developing chatbot systems and their evals, I realized how relevant software engineering principles are in this context. Specifically, iterating quickly reflects in faster & successful development, removing any guessworks. The success with AI hinges on how fast you can iterate.
For more on how to start building your evaluation systems, I recommend reading Hamel Hussain’s blog.
The Problem: Our Current Methods Fall Short
Yet, despite their clear importance, current chatbot evaluation methods are significantly limited. Typically designed around single-turn question-answer scenarios, these approaches inadequately capture the nuanced dynamics of conversational systems. Let me show you what I mean with a real conversation:
User: Can you share the outcomes of NVIDIA's board meeting?
Chatbot: Ofcourse, can you let me know which year board meeting are you looking for?
User: 2024
Chatbot: Based on my search, I found that .....
In this scenario, the chatbot demonstrates context-awareness by correctly engaging in follow-up interactions. However, traditional evaluation methods would penalize this exchange for not immediately providing complete information in the first response. This oversight highlights a fundamental flaw: conventional metrics simply cannot accurately assess performance across natural, evolving multi-turn conversations.
Here’s the disconnect: your users are perfectly happy with this conversational style, but your evaluation metrics are telling you something’s wrong. You could bring in human evaluators to rate satisfaction, but that doesn’t scale - you can’t have humans evaluate every conversation, every prompt change, every deployment. This is where LLMs come in. What if we could create an LLM that mimics human conversation patterns and systematically talks to your chatbot?
A New Approach: Let Agents Do the Talking
Here’s where things get interesting. Instead of forcing rigid metrics onto fluid conversations, what if we created agents that could actually have conversations with our chatbots? Think of it as automating conversation testing with agents that follow instructions and can scale as needed.
Our framework introduces two key players, each with a distinct purpose:
The User Agent (A curious user)
Think of this agent as your most thorough beta tester. They don’t just ask one question and move on - they dig deeper, ask follow-ups, and explore edge cases just like real users do.
What makes them special:
- They remember context from earlier in the conversation
- They ask natural follow-up questions based on what they’ve learned
- They know when they’ve gotten what they need (or when they haven’t)

Figure 2: Diagram of the UserAgent (left) holding a multi-turn conversation with the target chatbot (right), illustrating how the agent probes with follow-up questions just like a real user.
The Conversation Critic (LLM-as-a-Judge)
This is a simple LLM-as-a-judge which looks at the entire generated conversation and rates how the chatbot behaved. It evaluates key aspects like:
- Did the chatbot provide accurate information?
- Were responses complete without being overwhelming?
- Did the conversation flow naturally, or were there awkward pivots?
How It All Comes Together
Here’s how a typical evaluation unfolds:
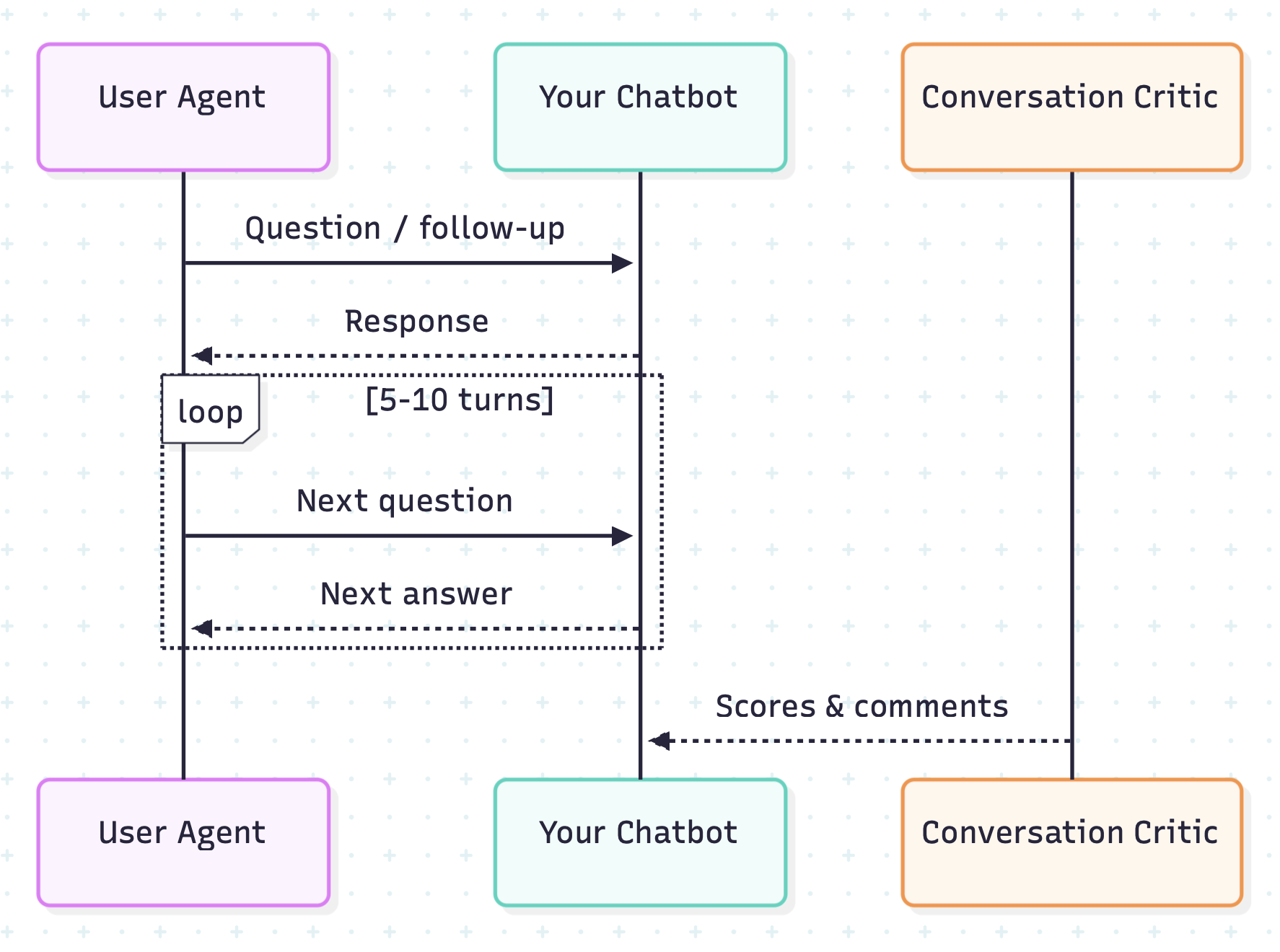
Figure 3: Sequence diagram of the evaluation loop: UserAgent ↔ Chatbot dialogue, Conversation history handed to the Conversation-Critic LLM, scores returned and logged for analysis.
Define the scenario: We define what we need- what questions need answering, what tone we’re aiming for, and what pitfalls to avoid. It’s like giving our agents a character brief before they step onto the conversational stage.
Play the scene: Our UserAgent initiates a conversation, playing the role of a curious customer. The chatbot responds, the agent follows up, and a natural dialogue emerges. Sometimes it’s smooth sailing; other times, it reveals surprising gaps in our chatbot’s abilities.
Critique: At the end, Conversation Critic rates the conversation across each dimension and logs comments.
What can we measure
We can evaluate the conversations the way humans actually experience them. For instance:
Conversation Completeness: Did we actually solve the user’s problem, or did we just throw information at them?
Natural Relevance: Do responses feel like they’re relevant to the user’s query?
Factual Integrity: We track both what the chatbot gets right and what it hallucinates.
Flow and Coherence: Can the chatbot handle when users change topics, circle back, or approach things from unexpected angles?
The Practical Benefits
The shift to this approach brings several advantages:
Scaling conversations: With user-agent, we can scale conversations to thousands of instances without burning out human testers. Imagine starting 1000s of simulations to catch rare and non-determinant bugs.
Real-World Relevance: These evaluations mirror actual user experiences, helping you build chatbots that align with how people naturally converse.
Rapid Iteration: Deploy changes with confidence. Within hours, you’ll know if that new prompt is helping or hurting the chat model’s performance.

Conclusion
Going forward, there’s a need for interactive evaluations. It’s hard but keeps us closer to human experience. As LLMs get powerful and align with human capabilities, it gives us a chance to make evaluations robust and closer to humans.
Leave a comment